
筆者在《廣義量詞的自然邏輯》一文中介紹了「自然邏輯」,即以貼近自然語言的表達式為基礎的邏輯推理。「自然邏輯」只是研究自然語言推理的眾多視角之一,本文嘗試從更廣闊的角度介紹自然語言推理的各種研究視角,希望讓讀者對這方面的研究趨勢有大略的認識,也讓讀者了解到「推理」是日常語言使用中的重要組成部分。下文將介紹語義/邏輯學、語用學、語法學和認知/心理語言學研究中有關自然語言推理的內容(註1)。請注意本文所說的「推理」,既包括邏輯學所研究的形式化推理,也包括日常語言使用中常見的非形式推理。
語義學(Semantics)與邏輯推理一向有非常密切的關係。這個學科的傳統形式-「詞匯語義學」(Lexical Semantics)便以詞匯之間的語義關係(例如「同義關係」Synonymy、「反義關係」Antonymy、「下義關係」Hyponymy等)作為重點研究的課題之一,而這些語義關係都與某種邏輯關係密切相關。舉例說,Cruse (1986)研究了多種「反義關係」,這些「反義關係」便體現著不同的邏輯關係,例如「黑」與「不黑」體現「矛盾關係」(Contradiction);「黑」與「白」體現「反對關係」(Contrariety);而「買」與「賣」則體現「逆關係」(Converse)。
二十世紀六、七十年代興起「形式語義學」(Formal Semantics)後,語義學界在研究中廣泛採用各種數學及邏輯學方法,自然語言推理順理成章成為語義學的研究課題之一。某些學者直接以自然語言推理作為研究對象,例如筆者在《廣義量詞的自然邏輯》一文中詳細介紹的「自然邏輯」(Natural Logic)研究,本文不予贅述。
其他語義學研究也或多或少涉及自然語言推理,並且常常以能否解釋或推導某些有效推理作為衡量其價值的準繩。舉例說,由Barwise and Cooper (1981)開創的「廣義量詞理論」(Generalized Quantifier Theory)便重點研究「單調性推理」。由Davidson (1967)開創的「事件語義學」(Event Semantics)則可用來解釋以下這種「論元結構推理」:
由Groenendijk and Stokhof (1984)開創的「劃分語義學」(Partition Semantics)則研究疑問句之間的推理,例如
請注意上列蘊涵關係應被理解為:如果我們得到「趙英愛誰」的圓滿解答,自然也會得到「趙英愛張三嗎」的圓滿解答。
無效推理對於當代語義學的發展也有重要的推動作用,因為某些語義學理論正是語義學家為了解決某些無效推理所引致的疑難而產生的。試看以下例子(在下例中,「∧」代表「並且」,「#⇒」代表「不蘊涵」):
(3)是「單調性推理」的反例,雖然「所有」具有「左遞減性」,但把其左論元「學生」換成真子集「富有的學生」後,結論不成立。這是因為該句的謂語「一起喝了」是「統指謂詞」(Collective Predicate),令「所有」的「左遞減性」失效。如把「一起喝了」改為普通的「逐指謂詞」(Distributive Predicate)「都各自喝了」,那麼該推理便是有效的。對「統指謂詞」和「逐指謂詞」的研究形成了當今語義學中有關「複數」(Plurality)的理論。
(4)是傳統邏輯中「替換原理」(Substitution Principle)的反例,雖然有等式「謝賢 = 謝霆鋒的父親」,但把第一個前提中的「謝賢」換成「謝霆鋒的父親」後,結論不成立。這是因為該句所含謂語「相信那人就是」是一種「晦暗謂詞」(Opaque Predicate),其語義解釋涉及張三的「信念世界」,令「替換原理」失效。如把「相信那人就是」改為普通的「透明謂詞」(Transparent Predicate)「打」,那麼該推理便是有效的。對「晦暗謂詞」和「透明謂詞」的研究形成了當今語義學中有關「內涵性」(Intensionality)的理論。
(5)是傳統「AAA-1三段論」的反例,雖然「小項」"one with a child"、「大項」"one who waters it"和「中項」"one who owns a garden"形式上滿足「AAA-1」格式,但結論不成立。這是因為這個推理所含代名詞"it"的所指呈動態變化,在第二個前提中指"the garden that he / she owns",但在結論中卻指"the child that he / she has"。如把"it"改為有固定所指的"the flowers",那麼該推理便是有效的。對在話語中呈動態變化的詞項的研究形成了「動態語義學」(Dynamic Semantics),是當今發展最快的語義學分支之一。
「古典邏輯」(Classical Logic)從一開始便與自然語言推理有密切的關係,它所研究的推理形式都是對自然語言句子的抽象。「古典邏輯」不僅嘗試找出有效的推理形式,而且還建立了一個推理系統,這個系統僅靠「周延」(Distribution)這個特殊概念和少數幾條規則,便能判斷任何「三段論推理」是否有效,這無疑是「古典邏輯」的一大成就。
及至「數理邏輯」(Mathematical Logic)興起後,某些「數理邏輯」學家(例如Russell)認為自然語言不精確,主張以精確的人工符號語言代替自然語言作為邏輯學的研究對象;而且很多「數理邏輯」學家認為「古典邏輯」中的推理結果可以被納入現代數理邏輯的框架下,「古典邏輯」遂喪失其中心地位,直至二十世紀後期才重新引起學者的注意,並成為當代「自然邏輯」的研究對象之一。
現代「數理邏輯」以及由其派生出來的「計算理論」(Computation Theory)從不同側面研究了邏輯推理的問題:「數理邏輯」既研究各種證明方式、推理規則和尋找證明的方法,也研究一個推理系統的各種「元邏輯性質」(Metalogical Property),例如這個系統會否推出互相矛盾的命題、能否推出所有在該系統下為真的命題等;「計算理論」則研究各種推理系統的「計算複雜性」(Computational Complexity)(即推理系統需要耗用多少步驟或記憶空間以完成推理)和「表達力」(Expressive Power)(即推理系統能夠表達哪些命題)等問題。
雖然上述研究並非針對自然語言推理,但現代「數理邏輯」很多有關推理的概念具有普適性,可用於某些涉及自然語言推理的研究領域,「計算語言學」(Computational Linguistics)(又稱「自然語言處理」Natural Language Processing)和「人工智能」(Artificial Intelligence)就是這樣的領域。「計算語言學」研究自然語言推理系統的各種計算性質和電腦實現問題,例如Moss、Pratt-Hartmann、Third、Calvanese、Thorne和Szymanik等人便使用「數理邏輯」研究各種自然語言推理系統的「元邏輯性質」、「計算複雜性」、「表達力」等問題,他們的研究範圍已遍及多種自然語言句型。Blackburn and Bos (2005)則以「數理邏輯」為基礎,研究「計算語義學」(Computational Semantics)的問題,其主旨就是用電腦程式來解決某些語義學和推理問題。
「人工智能」的一個目標就是要讓電腦明白人類的語言(口語或文字),並進行自動推理。當今「人工智能」的幾個應用領域,如「答問」(Question Answering)、「資料檢索及提取」(Information Retrieval and Extraction)、「機器翻譯」(Machine Translation)等都涉及自然語言推理,而近年來「人工智能」中一個非常熱門的課題「文本推理」(Textual Inference)更直接與自然語言推理有關。上述各方面的研究常常是建基於「數理邏輯」,例如Ali (1993)和Braz et al (2006)的研究。總上所述,儘管某些學者(例如研究「自然邏輯」的學者)認為「數理邏輯」的表達式與自然語言的句子結構格格不入,但由於「數理邏輯」在當代獲得長足發展,它仍是當今自然語言推理的一個重要研究工具和理論基礎(註2)。
邏輯學在當代已發展出眾多分支學科,其中較重要的分支包括各種「模態邏輯」(Modal Logic)、「多值邏輯」(Many-Valued Logic)、「非單調邏輯」(Non-Monotonic Logic)、「行動邏輯」(Logic of Action)、「非形式邏輯」(Informal Logic)、「圖式邏輯」(Diagrammatic Logic)等。在這眾多分支中,「非形式邏輯」和「圖式邏輯」值得特別一提,因為這兩種邏輯都用了現代數理邏輯認為不嚴謹的理論/方法來研究自然語言推理,拓展了邏輯學研究的視野。「非形式邏輯」可以Toulmin (2003)為代表,Toulmin (2003)把西方「修辭學」的理論應用於研究「三段論推理」,特別是省略了前提/結論的「修辭三段論」(Enthymeme)。「圖式邏輯」則研究如何直接用圖形進行邏輯推理(註3),例如Mineshima et al (2008)便把「歐拉圖」(Euler Diagram)用於研究「三段論推理」。有些學者更認為, 「圖式推理」將成為與傳統「符號推理」並立的新範式。
除了一般的推理外,當代還有某些語義學/邏輯學/數學學科針對自然語言中的某些特殊推理現象來進行研究。在這些現象中,「不確定性」(Uncertainty)是一個牽涉面極廣的現象,本節餘下部分將集中討論當代有關自然語言「不確定性」推理的研究。自然語言的「不確定性」大致上說有三個來源:「模糊性」、「或然性」和「歧義性」,以下分別介紹。
「模糊性」表現為某些自然語言概念沒有明晰的外延,對於某個個體與該概念外延的關係,不是簡單的「屬於/不屬於」的問題,而是「在多大程度上屬於」的問題,例如「高」就是模糊概念,某些高度肯定屬於「高」,某些高度肯定屬於「不高」,但還存在大量處於「模糊地帶」的高度,在不同程度上屬於「高」。
當代有多套研究「模糊性」(Vagueness)的理論,其中「模糊理論」(註4)(Fuzzy Theory)(註5)的研究隊伍陣容最為龐大。「模糊理論」的特點是把模糊概念表達為「模糊集」(Fuzzy Set),並用「隸屬度」(Membership Degree),即區間[0, 1]上的一個實數,來代表論域中的個體屬於某模糊集的程度,數字越大代表其隸屬程度越高,而數字1和0則分別代表「完全屬於」和「完全不屬於」。由此可見,「模糊集」是普通「明晰集」(Crisp Set)的推廣(註6),當論域中的個體對於某集合的「隸屬度」只取1和0這兩個數值時,這個集合就是「明晰集」。
Zadeh在初創「模糊理論」時,便已研究模糊概念的推理問題,是為「廣義模糊邏輯」(Fuzzy Logic in the Broad Sense)之發端,例如Zadeh (1983)就是模糊量化句推理研究的奠基性文獻。其後某些學者使用「數理邏輯」的概念,把Zadeh以實用為本的推理理論改造成嚴謹的現代「數理邏輯」分支,是為「狹義模糊邏輯」(Fuzzy Logic in the Narrow Sense),Bergmann (2008)是介紹這種邏輯的入門書籍。
模糊推理的特點是,不僅其前提及結論中的概念具有模糊性,而且推理本身的「有效性」(Validity)也可以是模糊的。以下是「模糊理論」早期研究的「廣義肯定前件律」(Generalized Modus Ponens)推理的例子:
| 前提1: | 若某番茄是紅色的,則它是熟的。 | (6) |
| 前提2: | 這個番茄非常紅。 | |
| 結論: | 這個番茄非常熟。 |
在上述推理中,「紅」和「熟」都是模糊集,前提1中條件句的真確性也是模糊的。不僅如此,由於前提2和結論多了「非常」這個「模糊限制詞」(Fuzzy Hedge),上述推理跟經典邏輯中的「肯定前件律」並不相同(註7),因此其「有效性」也是模糊的。「模糊邏輯」的一個目標,就是研究如何根據前提的模糊度估算結論「有效性」的模糊度。
「模糊理論」無疑是當今研究模糊性的學者中最多人採用的理論,但不是唯一選擇,以下介紹另外兩種理論-「粗糙理論」(Rough Theory)和「超級賦值理論」(Supervaluation Theory)。「粗糙理論」是指以Pawlak (1982)開創的「粗糙集合論」(Rough Set Theory)為基礎研究模糊現象的學科的統稱,這套理論採用「下近似」(Lower Approximation)和「上近似」(Upper Approximation)這對概念來刻劃模糊性。簡言之,對於某一模糊集S而言,其「下近似」包含論域中所有「肯定」屬於S的元素,其「上近似」則包含論域中所有「可能」屬於S的元素。這兩個集的差集稱為S的「邊界域」(Boundary Region),如果它是空集,S就是「明晰」的,否則就是「粗糙」的,由此可見「粗糙集」是「明晰集」的另一種推廣。雖然「粗糙集合論」與「模糊集合論」的某些重要概念可以互相定義,但「粗糙理論」有其獨特的理論和方法,因此與「模糊理論」存在某種互補關係。
由Fine (1975)、Kamp (1975)、Keefe (2000)等學者發展起來的「超級賦值理論」則與「模糊理論」處於對立關係,這些學者認為「模糊理論」的某些方法會導致不正確的結論,他們主張把模糊性看成「真值空隙」(Truth Value Gap),即把個體x處於模糊集S的模糊地帶處理成命題"x ∈ S"沒有真值。現設某命題p陳述某模糊集S與個體a、b、c等的關係,其中"a ∈ S"、"b ∈ S"、"c ∈ S"...沒有真值,因而令p的真值難以確定。「超級賦值」的意思就是把「真」或「假」逐一賦予"a ∈ S"、"b ∈ S"、"c ∈ S"...,從而使我們得以確定p的真值。當然,上述「超級賦值」有多種可能(例如某個「超級賦值」可以是"a ∈ S"真、"b ∈ S"假、"c ∈ S"真...;而另一個「超級賦值」則可以是"a ∈ S"假、"b ∈ S"真、"c ∈ S"假...)。如果在所有可能「超級賦值」下p都真,我們便說p是「超級真」(Supertrue)的;如果在所有可能「超級賦值」下p都假,我們便說p是「超級假」(Superfalse)的;如果在某些可能「超級賦值」下p真,在其他可能「超級賦值」下p假,我們便說p是真假不定的。
以矛盾式"b ∈ TALL ∧ b ∈ ¬TALL" (意即「b既高又不高」)為例,即使個體b處於「高」的模糊地帶,即"b ∈ TALL"和"b ∈ ¬TALL"沒有真值,但在任何可能「超級賦值」下,我們必有"b ∈ TALL"和"b ∈ ¬TALL"分別被賦予相反的真值,因而必有"b ∈ TALL ∧ b ∈ ¬TALL"假,由此可知這個矛盾命題是「超級假」的。從上述討論可知,「超級賦值理論」可以正確斷定某些特殊模糊命題(例如前述的矛盾式)的真值,但對其餘為數眾多的模糊命題,則把它們一律歸為真假不定而不作細致處理,因此其應用範圍沒有「模糊理論」那麼廣,我們可以說「超級賦值理論」與「模糊理論」各有千秋。
近年來,學者亦已開始研究「粗糙理論」和「超級賦值理論」下的邏輯推理問題,並指出其應用價值,例如Liu and Liu (2008)和Varzi (2007)便分別研究了「粗糙邏輯」和「超級賦值邏輯」。由於「粗糙理論」是作為一種信息處理工具而誕生的,它有很強的應用性,Liu and Liu (2008)便討論了「粗糙邏輯」在人工智能上的應用。「超級賦值理論」則較受哲學家和語義學家青睞,應用性本來不太強,但近年來亦有學者(例如Kulik (2001))把它應用於與「地理資訊系統」(Geograhical Information System)有關的空間推理,而筆者相信把「超級賦值理論」與「模糊理論」融合應可提升「超級賦值理論」的應用價值(註8)。
「或然性」(Stochasticity)是與「必然性」相對的概念,在自然語言中表現為某些「模態詞」(Modal Words),例如「可能」、「多半」、「難得」等。事實上,這些「模態詞」常常出現於自然語言推理的實例中。「概率論」(Probability Theory)是研究「或然性」的首要理論,把「概率論」與「演繹推理」(Deduction)相結合,便形成「概率邏輯」(Probability Logic)。這種邏輯的前提和結論是或然命題,其或然性由概率反映。對「概率邏輯」的研究可以有多種取向,有些人研究如何建構包含概率的公理系統,有些人(例如Adams (1998))則研究如何根據前提的概率估算結論的概率。
除了「演繹推理」外,「概率論」還可應用於多種「非演繹推理」,其中以「歸納推理」(Induction)最為重要。主流的邏輯學以研究具有必然性的「演繹推理」為主,但我們在日常生活中進行的推理卻大多數是具有或然性的「歸納推理」(註9)。「演繹推理」著重研究推理的「有效性」,與此不同,「歸納推理」注重推理的「歸納強度」(Inductive Strength),即前提在多大程度上支持結論。
「歸納推理」有多種形式,以往人們只把「歸納推理」理解為從個別事例推出一般情況的推理,例如從大量貓喜歡吃魚的事例和至今未發現不喜歡吃魚的貓的事例,推出「所有貓都喜歡吃魚」的結論。但上例其實只是多種「歸納推理」的一種可能形式-「概推」(Generalization),「歸納推理」尚有其他形式,例如以下的「統計三段論」(Statistical Syllogism)就是一種從一般情況推出個別事例的推理:
| 前提1: | 幾乎所有人都高於26吋。 | (7) |
| 前提2: | 張三是人。 | |
| 結論: | 張三高於26吋。 |
當代某些邏輯學家研究的「類比推理」(Analogy)和「溯因推理」(Abduction,亦譯作「逆證推理」)與「歸納推理」有密切關係。「類比推理」是指從某兩類事物具有某些已知相似特質,推出這兩類事物也同時具備其他某些未知的相似特質。例如根據張三和李四有相似興趣、性格、外形,兩人並無關鍵差別,以及張三受女生歡迎,從而推出李四也受女生歡迎。「類比推理」與普通「歸納推理」的聯繫在於,前者可以被看成對「特質」的歸納,而後者則是對「個體」的歸納。
「溯因推理」可被看成與「演繹推理」逆向的過程,後者是從給定的前提推出必然的結論,而前者則是從給定的結論/結果推出可解釋此一結論/結果的合理前提/原因。例如根據草坪濕了,以及剛才不是清晨出現露水的時間,也不是園丁或自動花灑灑水的時間,也不大可能曾有一群頑童在這裡玩擲水彈,從而推出剛才下過雨。「溯因推理」與「歸納推理」的聯繫在於,後者可被看成前者的特例,這是因為如果發現大量S類事物具有P特質,以及至今未發現任何不具備P特質的S類事物,那麼可解釋此一現象的一個合理原因就是「所有S類事物都具有P特質」。
以上所述的「非演繹推理」本來都是非形式的推理,不像「演繹推理」那樣有嚴謹的數理基礎。但近年來學界亦嘗試把這些推理建立在某些數學或邏輯學基礎上,例如把「歸納推理」建立在「統計學」(Statistics)的基礎上。事實上,「統計學」的研究內容本來便包含某些推理形分,稱為「統計推理」(Statistical Inference)。由於「統計學」的理論是建基於「概率論」,這使它自然成為研究具備或然性的「非演繹推理」的有力工具。另外亦有學者(例如Wang (2000))把「人工智能」的理論應用於「非演繹推理」,建立了一個包含「演繹推理」、「歸納推理」和「溯因推理」的三段論邏輯系統。
「歧義性」(Ambiguity)(註10)是自然語言的固有屬性,但歷來的學者較少研究歧義句的推理問題,他們所研究的推理問題大多是無歧義的人工語言或者經「解歧」(Disambiguation)後的自然語言表達式的推理問題。舉例說,英語句子
便有兩種解讀,可分別用以下限制性謂詞邏輯表達式來表示:
以上兩式就是把(8)「解歧」後的表達式,它們使用「∀」和「∃」的先後次序來代表兩種解讀,可分別稱為「∀取寬域」解讀和「∃取寬域」解讀,分別表達「對每個男孩x而言,都有至少一個女孩y,使得x愛y」和「有至少一個女孩y,使得對每個男孩x而言,都有x愛y」的意思。
歷來的學者在研究自然語言的歧義句時,大多先把這些歧義句改寫成「解歧」後的表達式,這實際上是迴避了歧義的問題。不過,當代也有一些學者專門研究歧義句的形式表達。Player (2004)對歧義句的各種形式表達理論作了綜述和分類,這些理論的共同特點是,使用同一個表達式代表帶有歧義的句子,即在生成歧義句的句法結構時不作「解歧」,把「解歧」留待對句子進行語義解釋時才進行。
此外,亦有學者研究歧義句的推理問題,Poesio (1991)可以說在這方面開創先河。雖然歧義句沒有單一語義,但只要小心定義, 我們也可以研究它們的推理問題。舉例說,從前述的句子(8),我們可以得到以下「單調性推理」:
上述推理中的前提和結論都是歧義句,都有「∀取寬域」和「∃取寬域」這兩種解讀。只要我們規定上述推理中的前提和結論同時採取「∀取寬域」解讀或「∃取寬域」解讀,便可保證上述推理成立。換句話說,上述推理其實包含著以下兩個推理:
由於對歧義句推理的研究須考慮有關句子的所有可能解讀,難度倍增,這方面的研究還是剛剛起步,研究成果不多,本文的介紹只能到此為止。
語用學(Pragmatics)研究各種超出字面意義或依賴於語境的意義,以及語言運用上的各種考慮因素,因此語用學研究的對象涉及語義和語言運用,這兩項都與推理密切相關。當今語用學研究的範圍很廣,其中較重要的研究領域包括對「隱涵」、「顯義」、「預設」和「言語行為」的研究,以下分別介紹這幾個領域與推理的關係。
「隱涵」(Implicature,亦譯作「寓義」或「含義」)是Grice (1975)提出的概念,指日常會話中的「言外之意」(註11)。Grice (1975)認為「隱涵」是「可計算」(Calculable)的,即可根據邏輯和某些原則推導出來。為此,他提出「合作原則」(Cooperative Principle)。此一原則假設談話者持合作的態度,即願意根據談話的目的和方向作出應有的貢獻。為使此一總原則具體化,Grice (1975)又提出假設談話者會遵守的四大準則:(I)「量準則」(Quantity Maxim),即提供當前談話所需的足量且適量的信息;(II)「質準則」(Quality Maxim),即不說虛假或缺乏證據的話;(III)「關係準則」(Relation Maxim),即談話內容須與當前話題相干;(IV)「方式準則」(Manner Maxim),即說話要簡明有條理,避免使用晦澀和有歧義的言語。
Grice (1975)提出上述原則及準則,是要說明人們如何推導出「言外之意」。試比較以下兩句:
由於(15) ⇒ (14),從信息量的角度看,(15)比(14)負載更多信息。假設當某人說出(14)時,他是合作的,那麼他應遵守「量準則」,即應已提供足量的信息,因此我們可以從他說出(14)推出他不知道(15)是真的,否則他便應說(15)而非(14)。如果我們再假設他知道每一位朋友的婚姻狀況,還可進而推出他知道(15)不真,即「他的朋友中並非所有人都結了婚」。以下把此一推理結果簡記作「(14) +> ¬(15)」(其中「+>」代表「隱涵」)。
請注意上述「隱涵推理」乃建基於兩個重要假設:說話者遵守「合作原則」及其下諸準則,以及說話者對當前談論的話題具有完全的知識。當然這種假設不一定成立,請注意以下說話是完全可以接受的:
(16)的第二句表明說話者在講第一句時沒有遵守「量準則」,因而須用「事實上」之後的說話來作出糾正;而(17)的第二句則表明說話者對當前話題只有局部知識。由此可見「隱涵推理」區別於一般邏輯推理的一個特點是,「隱涵推理」須依賴於一些邏輯系統以外的不一定成立的假設。此外,「隱涵推理」還具有「溯因推理」的特點,以前述的(14)為例,人們正是從(14)逆推出說話者知道(15)不真和說話者遵守「量準則」,以此作為對他說出(14)的合理解釋。正由於「溯因推理」並非「演繹推理」,「隱涵推理」的結論可被推翻。
Grice (1975)還區分了兩種「會話隱涵」:「一般會話隱涵」(Generalized Conversational Implicature)和「特殊會話隱涵」(Particularized Conversational Implicature),前者由特定的詞項引發,後者則由語境或背景知識引發。前述的「(14) +> ¬(15)」便是「一般會話隱涵」的例子,因為這個推理是由詞項「很多」引發的,即每當人們看到某句具有「很多X是Y」的形式時,便會自然推出「並非所有X是Y」此一「隱涵」。以下提供一個「特殊會話隱涵」的例子:
| A:Pierre住在哪裡? | (18) |
| B:法國南部某處。 |
在上述對話中,B的答語所含的信息量明顯不足(在通常情況下A所要求的答案至少應包含某個城市/鄉鎮名),違反了「量準則」。但若假設B是合作的,那麼根據「質準則」,B不應提供他不肯定的答案,由此可推斷出B的答語隱涵著他不知道Pierre住在法國南部的哪一處。請注意上述推理結果不能僅從某一特定詞項推得,而是須從當前語境加上背景知識(以及「合作原則」)才能推得,所以屬於「特殊會話隱涵」。
繼Grice (1975)之後,一些學者繼續研究「隱涵推理」的性質,提出各種不同的見解。以Horn (1989)和Levinson (2000)為代表的「新格賴斯學派」(Neo-Gricean School)主力研究「一般會話隱涵」,他們把Grice (1975)提出的諸準則重新組合為一些原則:(I)「Q原則」(Q-Principle),即提供充足的信息;(II)「R原則」(R-Principle),即只提供必要的信息(註12),並用這些原則來解釋各種「一般會話隱涵」。此外,由於「一般會話隱涵」乃由某些特定的詞項引發,他們認為這種「隱涵推理」具有「缺省推理」(Default Reasoning,亦譯作「默認推理」)的特徵。「缺省推理」是「非單調推理」的一種,這種推理容許前提有例外情況,因而所得結論僅在前提不屬例外的情況下才成立。以(14)為例,我們可以認為「很多」在「缺省」(即「非例外」)情況下總具有「並非所有」的意思,因此從(14)我們能夠缺省地推出¬(15)。Levinson (2000)更主張建構一種「缺省邏輯」(Default Logic)以作為「一般會話隱涵」的基礎理論,這項工作其後由張韌弦(2008)完成。
以Sperber and Wilson (1986)為代表的「關聯理論」(Relevance Theory)對「隱涵推理」持另一種看法。這套理論認為「隱涵推理」基本上是「演繹推理」,推理的前提就是先前談話的內容以及談話者的背景知識。由於這些前提非常多,「隱涵推理」的結論不可能是任何可從這些前提中推出的命題,而是以最小心力得到而與當前語境最相關的信息。「隱涵推理」跟一般「演繹推理」的區別在於,「隱涵推理」的前提往往是隱含和不確定的,所以其結論不是絕對的。以前述的(18)為例,根據B的答語,我們可以重構以下推理:
| 前提1: | 如果B知道Pierre住在法國南部的哪一處,他會在答語中講出。 | (19) |
| 前提2: | B在答語中沒有講出Pierre住在法國南部的哪一處。 | |
| 結論: | B不知道Pierre住在法國南部的哪一處。 |
上述推理體現了經典「演繹推理」的「否定後件律」(Modus Tollens)(參見註7)。上述「隱涵推理」的結論不是絕對的,假如在A的背景知識中包含著B知道Pierre的確切住址此一信息,那麼由B的答語引發的「隱涵推理」便不是(19)的形式,所得結論也可能變為:B不願講出Pierre住在法國南部的哪一處。
近年來,一些學者借用其他學科的理論(例如Blutner (1998)和van Rooij (2004)分別借用音系學上的「優選論」(Optimality Theory)和數學上的「博奕論」(Game Theory))來解釋「隱涵推理」,特別是前述的「Q原則」和「R原則」,分別形成「優選論語用學」(Optimality Theoretic Pragmatics)和「博奕論語用學」(Game Theoretic Pragmatics)。根據Horn (1989)和Levinson (2000),「Q原則」和「R原則」存在一定的矛盾,他們把很多語言現象看成這兩個原則角力的結果。此一觀點令「優選論」和「博奕論」得以在「隱涵推理」研究中有用武之地,這是因為「優選論」研究如何從互相矛盾的限制條件中選擇最優者,「博奕論」則研究對奕者如何根據各自的博奕策略達致最佳的賽果,而上述兩個原則的角力正可被看成某種「擇優」或「博奕」的過程。
經典的語用學把語句的意義區分為「真值條件義」和「隱涵」,「真值條件義」基本上包含不依賴於語境的字面意義(又稱「編碼義」Encoded Meaning)(註13)。語境對「真值條件義」的貢獻只有兩項:「解歧」和「指稱指派」(Reference Assignment)(即確定語句中某些代名詞和其他替代詞的所指)。「關聯理論」以及由其派生而來的「真值條件語用學」(Truth-Conditional Pragmatics)(以Recanati (2010)為代表)質疑上述觀點,這些理論的學者認為日常使用的語句有大量語義欠明之處,即使進行了「解歧」和「指稱指派」,仍然不能確定其真值條件,因此確定語句「真值條件義」的過程,絕非只是「解碼」+「解歧」+「指稱指派」那麼簡單,而是涉及更多語用推理。為此,他們提出一個新的概念-「顯義」(Explicature)以涵蓋經「解碼」和各種語用推理後所求得的意義總和,以下筆者將介紹「解碼」、「解歧」和「指稱指派」以外的其他類型的「顯義」。
日常使用的語句有很多略而不說的成分,此一現象既可以表現為語法上的省略結構,也可以是把句中謂詞的某些論元略去的結果,把這些略去的成分補出的過程稱為「充盈」(Saturation),例如
(20)的意思表面上很完整,但"winners"一詞是由及物動詞"win"派生而來的,所以這個詞其實隱含著一個賓語(即被勝出的事物),(21)補出了這個隱含的賓語-"the crossword puzzle competition"。
在某些情況下,「顯義」的推導不是要補出省略的部分,而是要令原句在當前語境下有更貼切的意思,這種過程稱為「調整」(Modulation),例如一位母親對著不小心切傷自己手指、正在哭著的小兒子說:
(22)的意思是完整的(假設已把「你」的指稱指派給那位小兒子),但我們不會把該句簡單理解為(22)的字面意義,因為若單從該句所表達的將來時間語義看,這個句子等同於說小兒子將來不會死,這顯然不是那位母親的意思。在一般情況下,我們會把(22)理解為包含著一個原因分句「因這個傷口」的(23)。
請注意在上述例子中,各種「顯義」都是由語用推理得到的,這種推理須依賴於當前語境和談話者的背景知識,不能單從句子的句法結構得出結論,這一點可從以下「指稱指派」的例子得到佐證:
以上兩例除了動詞賓語和介詞賓語外,具有完全相同的結構,但兩例中的"It"卻分別指向前句中處於不同位置的名詞短語(即加了下劃線的部分)。這個「指稱指派」的過程顯然依賴於我們對易碎物件的背景知識而非句法結構。而且上述「指稱指派」結果只是就一般情況而言,並不排除在特殊情況下有不同的結果。以(25)為例,如果前文已交代了有關杯子是用不碎玻璃造的,而有關牆壁是一堵普通玻璃牆,那麼(25)中的"It"便很可能指向前句的"the wall"而非"the glass"。
「預設」(Presupposition,亦譯作「先設」)本來是邏輯學家提出的概念,指命題具有真值的先決條件。在傳統的二值邏輯下,一個命題非真即假。但在日常語言中,這卻並不一定成立。試看以下例句:
以上兩句雖然看似互相矛盾,但卻不一定非真即假,這是因為這兩句以下列兩個命題作為「預設」(註14):
如果(28)或(29)不成立,(26)和(27)便無真假可言,以下把這種情況稱為「預設缺失」(Presupposition Failure)。
上述「預設」概念只適用於陳述句(即命題),稱為「語義預設」(Semantic Presupposition)。為擴大「預設」的適用性,某些學者(例如Stalnaker (1974))又提出「語用預設」(Pragmatic Presupposition)的概念,「語用預設」是指談話雙方關於某一詞項或語句的共有背景知識。試看以下例句:
容易看到,當某人說出(30)這個疑問句時,談話雙方的共有背景知識中必須包含(28)和(29)這兩個命題,否則他就是無的放矢或者用詞不當,因此(28)和(29)就是(30)的「語用預設」。以下筆者將以「預設」作為「語用預設」的簡稱。
「預設」概念大大改變了邏輯學和語言學研究的面貌,在當代出現了大批嘗試處理「預設」現象的邏輯學和語言學理論。由於「預設缺失」現象與「模糊」現象有一些共通點,即這兩者都打破了二值邏輯的常規,這兩種現象往往可以用同一種方法處理。舉例說,某些學者(例如Karttunen and Peters (1979)(註15))使用「多值邏輯」來解釋「預設」現象,這跟「模糊邏輯」有相通之處,因為「模糊邏輯」可被看成一種「無窮值邏輯」。van Fraassen (1969)則創立「超級賦值理論」,把「預設缺失」現象解釋成一種「真值空隙」。後來Fine (1975)等人把這套理論轉用於研究「模糊」現象,這在上文2.3.1節已介紹過。
在日常語言中,有一種現象涉及「預設」的推理,此即Lewis (1979)研究的「預設包容」(Presupposition Accommodation)現象。如前所述,如某句話語出現「預設缺失」,該句話語是不恰當的。可是在日常對話中,基於「合作原則」,我們通常不會輕易判定對方的話語出現「預設缺失」,而是採取一種包容的態度,在理解對方的話語時把必要的「預設」即場加入背景知識中。試看以下例句:
上句中出現了「有定限定詞」(Definite Determiner) "my",一般認為這類限定詞預設其後的名詞是存在的,因此上例中的第二句預設說話者有女兒。在日常語言使用中,(31)的聽話者不一定早已知道說話者有女兒,但通常都會進行「預設包容」,把這個命題即場加入背景知識中。上述例子顯示,「預設包容」其實是對話語中某些隱含或欠明信息的推理,因此跟前述的「隱涵」或「顯義」推理有相似之處。
邏輯學一般只研究陳述句的真假問題,但在日常語言的使用中,還有大量非陳述句不在邏輯學的研究範圍內(註16),因此Austin (1975)提出「言語行為理論」(Speech Act Theory)以補邏輯學的不足。Austin (1975)認為,可以把各種言語的使用看成「言語行為」,「言語行為理論」的主旨就是研究各種「言語行為」在甚麼情況下是恰當的,試看以下例句:
上述宣告句只有在說話者具備所需的權力並在適當的場合說出才是恰當的。由此可見,「言語行為理論」把傳統邏輯學對命題真值的研究轉化為對言語行為「恰當性」(Felicity)的研究,從而填補了在非陳述句研究方面的空白。
繼Austin (1975)之後,Searle (1975)繼續發展「言語行為理論」,並研究「間接言語行為」(Indirect Speech Act)的問題。「間接言語行為」是指以表面上的言語行為實現另一種言語行為的目的。舉例說,人們往往以問題的形式提出請求,例如在餐桌上某甲對某乙提出以下問題時:
甲實際上不是向乙提問,而是向乙提出一個請求,因此乙的合理回應不應只是就其遞鹽的能力作出回答,而應是把鹽遞給乙或者拒絕這樣做。Searle (1975)認為人們對「間接言語行為」的理解其實是「隱涵推理」的一種,因為「間接言語行為」像「隱涵」一樣,也是表達言外之意。
「言語行為理論」的另一個發展是Searle and Vandervekan (1985)開創的「語力邏輯」(Illocutionary Logic),以作為傳統真值邏輯的擴展。蔡曙山 (1998)則進一步把他們的框架發展為形式化的邏輯系統,使之成為現代邏輯的一個分支。在「語力邏輯」下,各種言語被看成把「語力」(Illocutionary Force)作用於「命題內容」(Propositional Content)的結果,例如前述(32)的「命題內容」和「語力」就分別是「你們是合法夫妻」和「宣告」。如用P和F分別代表「你們是合法夫妻」和「宣告」,便可把(32)表達為F(P)的形式。
建立了「語力邏輯」系統後,便可以進行「言語行為」的推理 ,以下是這種推理的兩個實例:
語法學(Grammar)一般分為「句法學」(Syntax,亦譯作「語形學」)和「形態學」(Morphology,亦譯作「詞法(學)」)這兩個分支,前者研究句法結構,後者研究各種形態現象和「構詞法」(Word Formation)。我們首先從「句法學」與推理的關係說起。由Chomsky (1957)開創的「生成語法」(Generative Grammar)的早期形式與邏輯推理有很相似的形式。Chomsky (1957)理論的特點是借用「電腦科學」上的「短語結構語法」(Phrase Structure Grammar)加上「轉換」(Transformation)操作來解釋自然語言的句法生成過程(註17)。舉例說,句子
便可以用以下「短語結構規則」生成:
| S | → NP + VP | (i) |
| NP | → Det + N | (ii) |
| VP | → V + NP | (iii) |
| Det | → the | (iv) |
| N | → boys | (v) |
| N | → teachers | (vi) |
| V | → love | (vii) |
在上列規則中,S、NP、VP、Det、N和V是句法成分,分別代表「句子」、「名詞短語」、「動詞短語」、「限定詞」、「名詞」和「動詞」;"the"、"boys"、"teachers"和"love"則是「詞庫」(Lexicon)中的詞項。這些句法成分和詞項合稱「符號」,而由「符號」和「+」號組成的結構稱為「符號串」。「→」則代表「改寫為」,即把「→」號左邊的符號改寫為其右邊的符號串,所以以上規則又稱「改寫規則」(Rewriting Rule)。容易看到,以"S"為起始點,我們可以使用以上改寫規則漸次生成對應於(36)的符號串:"the + boys + love + the + teachers"。
「生成語法」一般把句法結構表示成樹形圖,例如(36)的樹形圖就是:
但我們也可以把上述句法生成過程看成一種類似定理證明的過程,以下稱為「句法推理」(註18)。從形式上看,在一個公理系統中,一個定理T的證明是一個由命題組成的序列,這個序列的最後一個命題必須是T,序列中的每條命題(包括T)必須是某條「公理」(Axiom),或是由「公理」或前面的命題經推理規則推導出來的命題。這樣,我們可以把上面的(i)至(vii)看成公理。此外,還可以加上"S"作為一條「附加公理」,這條「公理」用於每一個證明的開首。這個系統只有以下一條推理規則:
請注意上述推理規則可被看成經典「肯定前件律」的推廣。利用上述「公理」和推理規則,便可以把生成(36)的過程看成以下證明過程:
| (1) | S | 附加公理 |
| (2) | S → NP + VP | 公理(i) |
| (3) | NP + VP | (1), (2), →− |
| (4) | NP → Det + N | 公理(ii) |
| (5) | Det + N + VP | (3), (4), →− |
| (6) | Det → the | 公理(iv) |
| (7) | the + N + VP | (5), (6), →− |
| ...... | ||
在上述證明中,第一欄為行號,第三欄代表某一行的理據,例如第(3)行的理據「(1), (2), →−」便代表把推理規則「→−」應用於第(1)和第(2)行上的命題所得的結果。為免使上述證明過於冗長,以上只提供這個證明的開首七行,讀者可自行完成這個證明,使這個證明的最後一行為"the + boys + love + the + teachers"。
對於「生成語法」學者來說,上述的「句法推理」還只是隱含著的概念;「範疇語法」(Categorial Grammar)則是明確以「句法推理」作為研究的對象。由於「範疇語法」支派繁多,以下僅介紹其某個重要支派「類型-邏輯語法」(Type-Logical Grammar)(以Carpenter (1997)為代表)的內容。「類型-邏輯語法」的特點是在「詞庫」中規定每一個詞的語義表達式和句法範疇,然後利用「自然演繹」(Natural Deduction)方法(註19)同時進行句法和語義推理,以同時生成句子及其語義表達式。
讓我們看一個簡單的例子,設我們的「詞庫」有以下內容:
| 詞項 | 語義表達式:句法範疇 |
|---|---|
其中"John"那一行的"j: NP"代表"John"這個詞的語義表達式是常項j,其句法範疇則是NP (即名詞短語)。
"loves"的語義表達式則是一個二重「λ表達式」(即一個「λ表達式」內包含另一個「λ表達式」)。「λ表達式」是現代「數理邏輯」和「形式語義學」中常用的工具,它代表一個函數,並由兩部分組成:第一部分包含"λ"符號及其後的「約束變元」(Bound Variable),第二部分由括號括起來,是函數的「主體」(Matrix)。前述的「約束變元」必須與「主體」內的某個函數論元相同。由於「λ表達式」本質上是函數,我們可以把它作用於適當的常項,其作用結果就是以該常項取代函數「主體」中與「約束變元」相同的那個論元,並同時消去"λ"符號及其後的「約束變元」,此一運算稱為「λ-還原」(λ-Reduction)。舉例說,設有「λ表達式」λy(DIE(y)),其中y就是「約束變元」,DIE(y)就是函數的「主體」,這個「主體」的論元y與前述「約束變元」相同。把這個函數作用於常項j,便有
| λy(DIE(y))(j) | |
| = | DIE(j) |
據此,前述"loves"的語義表達式實質上告訴我們,"loves"這個詞首先作用於其第二論元(亦即賓語),然後再作用於其第一論元(亦即主語)。
"loves"的句法範疇(NP\S)/NP是一個複合範疇,其中「\」和「/」可被分別看成現代數學中「映射」(Mapping)符號「→」的左向和右向變體。NP\S便代表一種向左作用的函數(請注意「函數」是「映射」的一種),當把此函數作用於一個位於其左面的名詞短語(NP)時,便會得到一個句子(S)。因此,NP\S其實代表「不及物動詞短語」,因為把一個「不及物動詞短語」與一個位於其左面的名詞短語結合後,可得到一個句子。同理,可知(NP\S)/NP其實代表「及物動詞短語」,因為把一個「及物動詞短語」與一個位於其右面的名詞短語結合後,可得到一個「不及物動詞短語」。
為進行推理,我們需要以下兩條「消去規則」(Elimination Rule,簡寫為"E"):

上圖左面的規則是說,如果在某行中出現左、右並排的兩個符號串「α: A」和「β: A\B」,其中α和β為任意語義表達式,A和B為任意句法範疇,那麼我們可以從這兩個符號串推得「β(α): B」。請注意在運用上述規則時,我們是同時進行語義表達式和句法範疇的推導,其中β(α)代表把β作用於α,而從A和A\B推得B的過程則類似經典「肯定前件律」的運用。
以上述詞庫作為前提,並輔以上述推理規則和「λ-還原」法則,便可以對"John loves Mary"作如下句法推理:

上述推理的最後一行告訴我們"John loves Mary"是一個句子(S),其語義表達式是LOVE(j, m),跟一般「謂詞邏輯」的表達式相同。
以上所述的「句法推理」嚴格地說是句法學家(而非一般人)頭腦中的推理。除此以外,一般人在日常語言使用中碰到的某些句法現象其實也包含語用推理的成分,以下僅舉「極性敏感詞」(Polarity Sensitive Item)作為例子。「極性」(Polarity)是指句子的肯定/否定性質(註20),「極性敏感詞」則是指經常用於肯定句或否定句的詞項。舉例說,英語的"some"和"any"便分別為「正極詞」和「負極詞」,分別經常用於肯定句和否定句中。在一般情況下,把它們分別放在否定句和肯定句會導致不合語法(註21),例如
傳統認為「極性敏感詞」屬於句法現象,「極性敏感詞」的使用是否合語法純粹視乎句子的「極性」。但有一些學者(例如Linebarger (1987))指出,「負極詞」有時也可以出現於某些帶有否定「預設」/「隱涵」的肯定句中。試比較以下兩句:
根據Linebarger (1987),(39)合語法是因為從該句可以推導出以下「隱涵」:
因此,"any"是在(39)的「隱涵」而非(39)本身取得合法性。反之,(40)卻沒有類似的「隱涵」,因此該句不合語法。由此可見,「極性敏感詞」此一句法現象受制於語用推理。
某些形態現象也涉及語用推理。上文第3.2節提到在日常語言使用中我們常須進行「顯義推理」,以補出句中各個詞欠明的意義。但欠明性不僅存在於詞匯層面,也存在於詞匯以下的形態/構詞層面。以英語的詞尾's為例,雖然這個詞尾傳統稱為「所有格詞尾」(Possessive Case Ending),但它所表達的意思遠遠不只「擁有」。事實上,根據Langacker (1991),這個詞尾表達非常籠統的關係。試看以下例子:
以上這個短語可以表達John與書的多種關係,這本書既可以是John擁有的,也可以是John寫的,還可以是John推薦的,甚至可以是John正在坐著的那本書。事實上,只要有適當的語境,這本書可以與John存在任何可能的關係。因此,人們必須根據語境補出(42)中John與書之間存在的關係,而這正是一種推導「顯義」的過程。
跟「所有格詞尾」相似,「複合詞」(Compound Word)中各個構成成分之間也可存在多種關係,試看以下例子:
以上幾個英語「複合詞」都包含"mill" (磨坊)這個中心成分,但"mill"與其前的修飾成分的關係卻各有不同。有趣的是,即使我們是第一次看見這幾個詞,也不難推斷出這些修飾成分與「碾磨」工序的幾種不同關係:"corn" (穀物)是「碾磨」工序的對象,"paint" (顏料)是「碾磨」工序的製品(「碾磨」的對象可能是某些木),而"wind" (風)則是「碾磨」工序所依賴的動力來源。以上例子顯示,「構詞法」只能籠統地告訴我們,「複合詞」中各個構成成分之間存在某種關係,至於是哪一種具體關係,可根據常識推斷出來。就這一點而言,我們對「複合詞」的理解過程與「顯義推理」有相似之處。
「認知語言學」(Cognitive Linguistics)是當今語言學中的一個重要流派,該流派認為語義、語用、語法互相關連,彼此沒有清晰的界限,因此主張進行綜合研究,與主張「句法自主」(即在研究句法時應盡量排除語義、語用因素)的「生成語法」形成尖銳的對立。此外,「認知語言學」也主張把「認知科學」(Cognitive Science)的研究成果應用於語言學研究中。「心理語言學」(Psycholinguistics)則是語言學中的一個分支學科 ,其主旨是把心理學方法應用於語言研究。由於「認知科學」也應用心理學的知識和方法,所以「認知語言學」與「心理語言學」有一些相通之處。以下介紹認知/心理語言學的幾個研究領域與推理的關係。
「梯級模型」(Scalar Model)是由「認知語言學」學者Fauconnier (1975)、Fillmore et al (1988)、Kay (1990)和Israel (1996, 2011)相繼發展起來的理論。Fauconnier (1975)最早提出對「梯級推理」(Scalar Reasoning)(註22)的研究,「梯級推理」是一種建基於「梯級」(Scale)的衍推推理。舉例說,設有以下「欄高梯級」:
那麼根據常識,我們可以得到以下推理:
以上推理是一種對「可能趨勢」而非「已然事實」的推理,即如果張三跳得過中欄,那麼照此趨勢推斷,在一般情況下張三應也跳得過低欄。當然這只是就「趨勢」和「一般情況」而言,實際上張三可能因種種原因而跳不過低欄,因此「梯級推理」與具有必然性的邏輯推理有別。
「梯級推理」雖然沒有必然性,但卻是日常語言中極常見的現象,Israel (2011)更認為它是人類認知活動中的一個基本範疇,多位學者用它來解釋多種語言結構的語義/語用特點。舉例說,Fauconnier (1975)便用「梯級推理」來解釋形容詞/副詞「最高級」(Superlative Degree)為何有時可表達「所有」、「任何」的意思,例如
在一般情況下,(45)可理解為具有(46)的意思。這裡便包含著「梯級推理」:對一般人而言,越是美味的食物越是想吃。如果某人不吃最美味的食物,那麼照此趨勢推斷,其他不那麼美味的食物自然也不吃,由此便可推出那人甚麼食物都不吃。有關「梯級推理」的詳細介紹,請參閱拙文《日常語言中的梯級推理》或周家發 (2011)。
「心理空間理論」(Mental Space Theory)是Fauconnier (1985)提出的理論。「心理空間」(Mental Space)是指句子或詞語描述的某個情景。人類思維的特點是擅長構想各種非現實情景,而且可以在一段說話中不斷更換情景,甚至可以把自己代入某一情景,從該情景中進行推理,這種思維需要一種對非現實可能性的抽象推理能力。以下提供一個典型例子(為方便討論,下文的每句前都加了標籤):
| (A) Max is 23. (B) He has lived abroad. (C) In 1990, he lived in Rome. (D) In 1991, he would move to Venice. (E) He would then have lived a year in Rome. | (47) |
上文的(A)句開始敘述Max的故事,我們可以說這句開啟了一個「心理空間」S1。B句開啟了一個新的空間S2,這個空間的時間相對於S1來說是過去時間。C句開啟了另一個空間S3,S3的時間(1990年)是相對於S1來說的另一個過去時間。接著D句開啟新空間S4,S4的時間(1991年)雖然相對於S1來說是過去時間,但相對於S3來說卻是將來時間,所以這裡用了表示「過去將來時間」的語法形式"would move",「過去將來時間」正是一種把自己代入某個過去時間從而展望將來的抽象時間觀點。最後E句使用複雜的「過去將來完成時間」形式"would have lived"描述一個推理結果:說話者立足於1990年,預期到1991年時將已住在羅馬一年。請注意這裡涉及三重非現實性:1990年相對於說話者所處的時間(即S1的時間)來說是過去的時間,被預期的1991年相對於1990年來說卻是將來的時間,而住在羅馬的一年相對於1991年來說又是已成過去的時間。上述分析顯示,人類能夠處理複雜的情景代入推理。
其後,「心理空間理論」又進一步發展為「概念合成理論」(Conceptual Blending Theory)(又稱「概念整合理論」Conceptual Integration Theory)(以Fauconnier and Turner (2002)為代表作)。這套理論顯示人類不僅有豐富的想像力,可以想像出不同的情景;而且還有無窮創意,可以把這些情景揉合成新的情景。
「概念合成理論」使用三類空間,第一類是「輸入空間」(Input Space)(可以有多個,至少須有兩個),為揉合提供素材;第二類是「通用空間」(Generic Space),反映各個「輸入空間」共有的概念結構;最後一類是「合成空間」(Blend Space),此即把上述素材進行揉合的場所,揉合的結果會產生各個「輸入空間」所沒有的新關係。我們用以下例子說明上述概念:
(48)來自「思想者」論壇一篇題為《譯名問題:碧咸與貝克漢姆較勁》的專題文章中的留言,文章作者鄭紹基(筆名zhengzi)在該則留言中指出泰國女首相Yingluck Shinawatra的中文譯名有六個之多:英拉、 盈拉、英祿、仁樂、英叻、丘英樂,提出下次如要撰文討論譯名不一的問題,可不妨以(48)作為標題。上述標題可用前述概念表示為下圖:
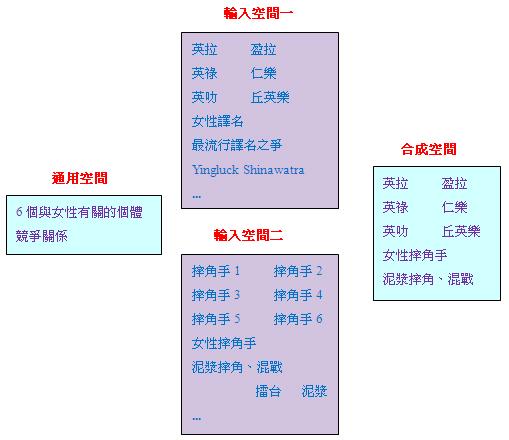
上圖顯示四個空間,其中兩個「輸入空間」中首五行 的八個元素存在對應關係,即「英拉」↔ 「摔角手1」...「最流行譯名之爭」↔ 「泥漿摔角、混戰」,其餘的元素則沒有對應關係。「通用空間」總結了兩個「輸入空間」的共通點,即六個與女性有關的個體之間的競爭關係。「合成空間」則從兩個「輸入空間」中各抽出部分元素,進行揉合,其結果就是(48)。請注意「合成空間」中出現了一些新關係,例如「英拉」、「盈拉」本來是同一個人的譯名,現在成了女性摔角手,並且參加混戰。
我們可以把理解(48)的過程看成一種「隱喻推理」(Metaphorical Reasoning),即以摔角手之間的較勁隱喻譯名之間的競爭關係。事實上,「概念合成理論」被廣泛用來解釋自然語言中的「隱喻」(Metaphor)現象。「隱喻」本來是指一種修辭技巧,即用具體直觀的事物比附抽象隱晦的事物,比附時並不使用明確的比附標記(例如「像」、「好比」等)(註23)。Lakoff and Johnson (1980)指出,「隱喻」不僅是修辭技巧,而且是自然語言中廣泛存在的現象,例如漢語方位詞「上」、「中」、「下」等本來表達空間關係,但常被用來隱喻各種抽象關係。因此「隱喻推理」是人類思維中很常見的推理形式,例如有些數學教育家指出人們在數學思維中便經常使用「隱喻推理」。對「概念合成理論」的研究將有助深入認識這種推理形式。
當代亦出現了自然語言推理的心理學研究,以下簡介這方面的一些重要理論或研究成果。以Bucciarelli and Johnson-Laird (1999)為代表的「心理模型理論」(Mental Model Theory)研究「三段論」推理的心理過程,認為一般人是根據邏輯規則進行推理,其具體操作方法則是構建「心理模型」。這些「心理模型」用少數幾行代表「三段論」中的每一個前提,例如前提「有S是M」便可以表示為
| s | m |
| s | |
| m |
上面每一行代表一個個體,第一行代表既是S又是M的個體,第二行代表是S但非M的個體,第三行代表是M但非S的個體。「心理模型理論」認為人們在進行「三段論」推理時,是先把兩個前提轉化為「心理模型」,並將其合併,得出一些可能結論,然後再嘗試構造反例,以排除掉無效的結論,最後剩下的結論就是該「三段論」的有效結論。
Oaksford and Chater (2007)的「概率法則模型」(Probability Heuristics Model)則認為人類的心智主要是用來處理含不確定性的推理而非確定的邏輯推理,因此一般人是採用概率思維而非邏輯規則進行推理。他們提出一些「法則」作為一般人進行「三段論」的心理依據(註24),這些「法則」是從大量日常經驗中總結出來的,雖有很高的概率,但並非完全確定。例如有一條「法則」是說:避免推出形如「有S不是P」的結論,因為這種結論所述的事實概率極高,因而只有很低的信息量(或認知意義)。這條「法則」反映人們在推理時,總希望得出有認知意義的結論。請注意根據這些「法則」,有時會得到無效的結論。但Oaksford and Chater (2007)的研究目標不是教人進行「三段論」推理,而是解釋一般人如何進行這種推理,包括出錯的心理機制。由此可見,推理的心理學研究與一般的推理研究有很不相同的研究目標。
除了「三段論」外,也有學者從事「廣義量詞」的心理學研究,較早期的代表作是Moxey and Sanford (1993)。通過心理實驗,他們發現不同的量詞會觸發不同的「指稱指派推理」,試比較以下例句:
以上兩例的第二句都包含代名詞"they",其所指與前一句的主語在兩例中有很不同的關係。(49)中的"they"指向前一句主語所指的至少三名志願者;而(50)中的"they"卻並不指向前一句主語所指的少數球迷,而是這些球迷相對於全體球迷的「補集」(Complement Set),即那些沒有去現場看足球賽的球迷。單憑傳統「廣義量詞理論」對"at least three"和"few"這兩個量詞所定的真值條件,難以解釋上述現象。這告訴我們須對這些量詞作更細致的分析,近年來某些研究「廣義量詞」的學者正是以此作為研究方向。
近年來越來越多學者把心理學實驗方法用於研究語用推理,尤其是對「隱涵推理」的研究,儼然有形成「實驗語用學」(Experimental Pragmatics)之勢,這些研究的目的是要借助心理學實驗以圖解決某些在語用學上爭論不休的問題。舉例說,Zondervan (2006)便利用心理學實驗研究「梯級隱涵推理」,即以下這種推理:
以往有些學者(可稱為「缺省派」Defaultist)認為「梯級隱涵推理」是一種無需依賴語境的「缺省推理」(詳見上文第3.1小節的介紹),但亦有學者(可稱為「語境派」Contextualist)認為「梯級隱涵推理」須依賴語境,Zondervan (2006)嘗試解決這個爭論,他的研究雖然沒有產生壓倒性結果,但對「語境派」的主張略為有利。
通過本文,相信讀者應已了解到推理在自然語言中的普遍性和重要性。在結束本文前,筆者必須指出,自然語言中仍有很多現象不能解釋為推理,例如語音-語義結合關係的任意性,某些語法現象和各種習語的無理據性等。這些現象只能用「編碼-解碼」來解釋,或者看成個別語言中的「特殊現象」(Idiosyncrasy)。如何理清這些現象與自然語言推理的分工關係,是有待研究的課題。
註1:「自然語言推理」一名有廣狹二義。廣義的「自然語言推理」泛指自然語言中的各種推理,狹義的「自然語言推理」則是當今「計算語言學」的一個分支研究領域,其英文名稱為"Natural Language Inference",簡稱NLI,本文討論的是廣義的「自然語言推理」。

