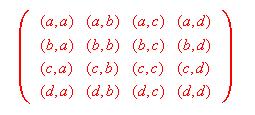
在前面兩章,筆者介紹了各種「迭代量詞」和量詞的「迭代」運算,有效解釋了如何運用「迭代」運算從「單式量詞」的真值條件推導出很多「多式量詞」的真值條件。可是,在自然語言中,還有很多「多式量詞」的真值條件不能透過「迭代」運算求得,這些量詞就是本文要介紹的「非迭代多式量詞」(Non-Iterated Polyadic Quantifier)。當前學界對「非迭代多式量詞」的研究大多集中於研究如何證明這類量詞的「非迭代性」。但由於這牽涉到頗為艱深的理論,本文只擬介紹「非迭代多式量詞」的各種類別及其真值條件,將不涉及「非迭代性」的證明。
筆者在《廣義量詞系列:基本單式量詞》中曾介紹「布爾量詞」,這種量詞是由「單式量詞」通過各種「布爾運算」(包括「否定」、「合取」、「析取」等)而得的複合結構。現在如果我們把上述定義推廣為由「迭代量詞」通過各種「布爾運算」而得的複合結構,便得到「一元複合體」(Unary Complex)的概念。請注意根據上述定義,以往介紹的「單式量詞」和「迭代量詞」都是「一元複合體」的特例。此外,還有一些既非「單式量詞」亦非「迭代量詞」的「一元複合體」。試看以下例句:
上句的真值條件可以用很簡單的方式表達為:
但問題是上式無法用筆者以往介紹的「迭代」運算推導出來,一個折衷辦法是把上句改寫為
假如把上句中的"any"處理成等同於"some" (註1),便可以把語句(1)表達為:
請注意上式是用「∧」連接兩個「迭代量詞」,但上式本身不能化歸為一個「迭代量詞」。現在如果我們運用上一章介紹的「迭代」運算,便可推導出上式的真值條件為:
上式在邏輯上等同於上面的(2)。由此可見,語句(1)的確包含了「非迭代多式量詞」,而這種量詞可以表達為「一元複合體」。
筆者以往介紹的量詞絕大多數都是以「個體集合」作為其「名詞性論元」。可是,在某些情況下,某些量詞也可以「有序n元組集合」或「無序n元組集合」(註2)(以下把「有序n元組集合」和「無序n元組集合」統稱為「n元組集合」)作為其「名詞性論元」。舉例說,前述的語句(1)相當於以下意思:
容易看到上句的論元結構近似「<1,1>型單式量詞」(no ... except John)U(A1)(B1)的論元結構(這裡的量詞(no ... except John)帶有下標U是為了強調這個量詞是定義在「個體論域」U中,而集合A和B帶有下標1是為了強調這兩個 集合是「個體集合」),這個「單式量詞」的真值條件為:
現在如果我們把上式中的"John"和j分別換成「有序對」(John, Bill)和(j, b),並把「個體集合」A1和B1換成「有序對集合」A2和B2,便可得到一個新的量詞。為了區別新舊兩種量詞,我們用符號Res2(no ... except (John, Bill)U)來代表這個新的量詞。利用這個新量詞並設定A2 = STUDENT2,B2 = WAIT-FOR,我們便可以寫出語句(3)的真值條件:
上式右端完全等同於上面的(2)。
請注意經上述變換後,Res2(no ... except (John, Bill)U)已不是原來的「<1,1>型量詞」,而是「<2,2>型量詞」,因為該量詞是以「二元組集合」A2和B2作為其「名詞性論元」和「謂詞性論元」。一般地,設有「<1,1>型量詞」QU(A1)(B1),其中A1和B1為「個體集合」。如果我們把A1和B1換成「n元組集合」An和Bn,便可得到「< n,n >型量詞」Resn(QU)(An)(Bn),並且
上式告訴我們,Resn(QU)相當於把Q的論域從原來的「個體論域」U提升為「n元組論域」Un,而Q與其論元之間的邏輯關係維持不變。上述這種把QU變換為Resn(QU)的運算稱為「概括」(Resumption),經此運算產生的「多式量詞」稱為「概括量詞」(Resumptive Quantifier)。
請注意「概括量詞」特別適用於作為表示成雙成對個體的名詞短語的限定詞。以語句"Most twins are identical."為例,由於「相同」關係只能存在於兩個或以上的個體之間,上句最適宜用以下的「<2,2>型量詞」表達:
請注意由於「雙生兒」和「相同」這兩個概念是對稱和無次序的,我們把上式中的TWIN和IDENTICAL(e(X'))規定為由「無序對」(Unordered Pair)組成的集合。
我們還可以應用「概括」運算來處理「多重疑問句」。根據《廣義量詞系列:特殊單式量詞》,「<1,1,1>型疑問量詞」"whichU"的真值條件為(這裡略去疑問句的預設):
如果對上式進行「概括」運算,便可得到以下這個「<2,2,2>型疑問量詞」及其真值條件(請注意我們也要把「語境集」X變換成其「笛卡爾積」X2):
由於在自然語言中,「多重疑問句」的一般形式為包含多個"which",並且各個"which"各自帶有「名詞中心語」(例如"Which boys love which girls?"),所以我們可以把上式中的Res2(whichU)分拆為(which ... which)U2,並把「有序對集合」A2寫成「笛卡爾積」 D1 × D1'的形式,這樣 上式便可以改寫為
請注意上式在實質上等同於《廣義量詞系列:迭代量詞》中表6第二行的真值條件(註3)。
「概括量詞」在「形式語義學」上有很高的重要性,因為這類量詞與「量化狀語」(Adverbial of Quantification)有密切關係。「量化狀語」是指"always"、"often"、"usually"、"sometimes"、"seldom"、"never"等詞語,語法學界一般把這些詞語視作「時間狀語」。可是,Lewis在Adverbs of Quantification一文中指出,這些「量化狀語」除了可用來對「時間」進行量化外,還可用來對各種「情況」(Case)進行量化。他並提出「無選擇約束」(Unselective Binding)的概念,指出跟普通的量詞只約束一個變項不同,「量化狀語」可無選擇地同時約束命題中的多個變項。利用上述概念,可以解決語義學上著名的「驢子句」(Donkey Sentence)問題(註4)。試看以下例句:
上句雖然含有「不定名詞短語」"a donkey",但Lewis並不把這裡的"a"分析成存在量詞「∃」,而是把這個短語視為引入一個未經量化的變項y,這個y與由「不定名詞短語」"every farmer"引入的另一變項x同時受全稱量詞「∀」的「無選擇約束」,因此上句的邏輯式應為
上述分析是合理的,因為語句(4)的正確意思是,就每個農夫而言,他有多少頭驢子,他就打多少頭驢子。如果把語句(4)中的"a"翻譯成「∃」便不能表達這個意思。
從「概括量詞」的角度看,我們可以把語句(4)中的"every"處理成「概括量詞」Res2(everyU)。由於該句含有一個「關係分句」,我們可以採用筆者以往介紹的處理「定語分句」的方法把該句的"farmer who owns a donkey"翻譯為(FARMER × DONKEY) ∩ OWN (註5),這樣該句的真值條件便是
讀者可自行驗證上式右端所表達的正是(5)所表達的意思。
根據謂詞邏輯,當一個邏輯式包含多個量詞時,靠右的量詞處於靠左的量詞的「轄域」之內。「轄域」問題是謂詞邏輯中的一個重要問題,因為它影響到量詞之間的「邏輯依存」(Logical Dependence)。所謂「邏輯依存」,是指當「存在量詞」處於「全稱量詞」的「轄域」內時,「存在量詞」所約束的變項的所指依賴於「全稱量詞」所約束的變項的所指。但當「全稱量詞」處於「存在量詞」的「轄域」內時,卻不存在上述的「邏輯依存」關係(註6)。舉例說,語句"Every boy loves some girl."有兩種含義,它們的「限制性量化」表達式分別為
在上面第一式中,y的所指會隨著x的所指而變化,即不同男孩所愛的女孩可能各有不同。而在第二式中,x的所指卻不會隨著y的所指而變化,這是因為x受「∀」約束,它的所指反正要窮盡BOY中所有元素,所以不受y影響。
為了突出存在於上面第一式的「邏輯依存」關係,我們可以把該式中的y改為一個函項f,這個函項把BOY中每個元素x映射到GIRL中某個元素y,其類型可表示為(BOY → GIRL)(註7)。請注意只有上述函項的值(即f(x))依存於x,而該函項f本身並不依存於x,所以我們可以把「∃f」移至「∀x」之前(即移離「∀x」的「轄域」),從而把上式改寫為以下的「高階謂詞邏輯表達式」(註8)(上面第二式維持不變),以上這種變換在邏輯學上稱為「斯科林化」(Skolemization):
上式亦可以用「廣義量詞理論」的集合論語言表達為
當句中出現多個「全稱量詞」和「存在量詞」時,便可能存在更複雜的「邏輯依存」關係。試考慮以下邏輯式:
在上式中,約束w的「∃」處於兩個「∀」的「轄域」內,其所指同時依賴於x和z的所指,所以我們可以把w改寫為一個類型為((A × C) → D)的函項g,其輸出值為g(x, z);而y的所指則僅依賴於x的所指,可以改寫為f,其輸出值為f(x)。至於x和z,則不依賴於其他變項。因此上式可改寫為
根據上一小節,邏輯式中各量詞之間的「邏輯依存」關係取決於這些量詞的線性排列次序。可是在自然語言中,有時會出現句中各量詞互不依存的情況。試看以下例句:
在上句中,"most girls"雖然位於"all men"的右邊,但女孩的所指顯然並不依賴於男人的所指,因為這句中的"most girls"是一個固定的集合,該集合中的每一個成員都是"all men"的每一個成員的學生。反過來看,男人的所指也顯然並不依賴於女孩的所指。由此可見,上句量詞的線性排列次序不能準確反映該句的語義,為此有些學者主張把上句的論元結構表達為以下這種非線性形式:
| all(MAN) | (TEACHER) |
| most(GIRL) |
上式顯示all(MAN)與most(GIRL)處於平行的地位,因此兩者互不依賴於對方(註9)。由於上式呈左向分枝形狀,我們把語句(6)中的量詞稱為「分枝量詞」(Branching Quantifier),並把它寫成Br2(all, most),它是一個「<<1,1>,2>型量詞」,其真值條件為:
上述真值條件是說存在一個MAN的子集C,它包含MAN的全部元素,並且存在一個GIRL的子集D,它包含GIRL中多數元素,並且C中每一元素與D中每一元素存在TEACHER關係。
對於「分枝量詞」的真值條件,歷來有很多學者曾進行研究,可謂眾說紛紜。事實上,以上筆者只介紹了爭議最少的情況,即處於平行地位的量詞都是「右遞增」(Right Increasing)量詞的情況。一個「<1,1>型量詞」Q是「右遞增」的當且僅當若Q(A)(B)並且B ⊆ B',則有Q(A)(B')。很多常用的「<1,1>型量詞」,例如"all"、"some"、"(at least n)"、"(more than n)"、"most"等都是「右遞增」的。現在我們把上式推廣到一般情況,從而得到以下有關「分枝」(Branching)運算的定義。設有「<1,1>型右遞增量詞」Q1 ... Qn,這些量詞各有一個「一元名詞性論元」A1 ... An,並共用一個「n元謂詞性論元」B,則有以下「<<1,...,1>,n>型量詞」:
至於其他並非「<1,1>型右遞增量詞」的情況,由於存在頗多爭議,本文不予討論。
筆者在《廣義量詞系列:特殊單式量詞》中介紹了「複數名詞短語」的三種常見解讀-「逐指解」、「統指解」和「分部解」。但「複數名詞短語」其實還可能有第四種解讀,試看以下例句:
上句的主語和賓語均為「複數名詞短語」,若純粹考慮以"eight examiners"、"100 candidates"和"interviewed"為主語、賓語和謂語動詞所產生的句子可以含有多少種意思,那麼由於上述兩個「複數名詞短語」可能含有多種解讀,而且主、賓語可以有多種「轄域」組合,這將產生很多解讀。為簡化討論,我們只考慮"100 candidates"作「逐指解」並且取「窄域」的情況。在此條件下,當"eight examiners"作「逐指解」時,所產生的句子的意思為「八名主考員各自會見了100名考生」;作「統指解」時,所產生的句子的意思為「八名主考員一起會見了100名考生」;作「分部解」時,所產生的句子的意思為「八名主考員分為若干小組,各個小組各自會見了100名考生」。可是以上三種解讀似乎都不是語句(7)所要表達的意思,該句的準確意思應為「八名主考員合共會見了100名考生」,至於這八名主考員究竟是各自、分組還是一起會見那些考生,則沒有具體說明。我們把上述第四種解讀稱為「累指解」(Cumulative Reading),並把含有這種解讀的量詞稱為「累指量詞」(Cumulative Quantifier)。
仿照上面各節的做法,我們可以把語句(7)的「累指量詞」寫成Cum2((exactly 8), (exactly 100))的形式。這是一個「<<1,1>,2>型量詞」,其真值條件為:
把上述的「累指解」跟其他解讀比較一下,我們會發現「累指解」含有最少信息,因為這種解讀只分別交代了那些會見了考生的主考員的數目以及那些被主考員會見的考生的數目,至於主考員和考生之間如何組合,則完全沒有交代。正因如此,在「累指解」下兩個「複數名詞短語」的「轄域」也是互不統屬,因此「累指量詞」有點類似「分枝量詞」(註10)。不過「累指量詞」所含的語義信息較「分枝量詞」為少,所以較適宜把「累指量詞」單獨列作「非迭代多式量詞」的一種。
我們可以把上式推廣為一般的「累指」(Cumulation)運算。設有「<1,1>型量詞」Q1 ... Qn,這些量詞各有一個「一元名詞性論元」A1 ... An,並共用一個「n元謂詞性論元」B,則有以下「<<1,...,1>,n>型量詞」:
上述「累指」運算亦可以應用於疑問句,但要作出適當調整。筆者在《廣義量詞系列:迭代量詞》中曾指出,以下疑問句有一種「累指解」:
由於在「累指解」下,上述疑問句實際是由兩個子問題組成的複合問題:「哪些男孩被狗咬了以及哪些狗咬了男孩?」,該句的「解答論元」應為由兩個集合組成的「有序對」,每個集合對應著上述複合問題的每個子問題的解答,因此上述疑問句應表達為以下的「<<1,1>,2,2>型量詞」:
現設上述疑問句的解答為"Dolly and Fido bit John and Bill.",這相當於提供了以下「解答集」A:
由於學界對「累指疑問句」的研究很少,而且這類疑問句的真值條件無法用「迭代」運算從「單式疑問量詞」的真值條件推導出來,這裡無法提供一般「累指疑問句」的真值條件。
英語有一種「相互代名詞」(Reciprocal Pronoun)(包括"each other"和"one another"這兩個詞),在句中專門充當賓語,表達某種相互關係(註11)。由於「相互代名詞」的一般語法功能類似一個名詞短語,我們可以把「相互代名詞」處理成「普通相互量詞」(Common Reciprocal Quantifier),記作Crq2(Q)的形式,這是一個「<1,2>型量詞」,含有一個「一元名詞性論元」和一個「二元謂詞性論元」(註12)。不過,由於「相互代名詞」可以表達多種相互關係,這裡的Crq2(Q)也有多種真值條件。Peters和 Westerstahl在Quantifiers in Language and Logic一書中總結了各種相互關係,本文僅介紹其中最重要的兩種,並把體現這兩種相互關係的「普通相互量詞」分別記作Crq12(Q)和Crq22(Q)。以下兩個例句分別含有這兩種「普通相互量詞」:
語句(8)體現了最直觀的相互關係,該句的意思是說,某家庭中的每一個成員都愛所有其他成員(但不一定愛自己)。為了表達這種相互關係,某些學者借用數理邏輯上的「藍姆賽量詞」(Ramsey Quantifier),把語句(8)的真值條件寫成:
在上式中,D是由FAMILY中所有成員組成的集合,D2則是由D中成員組成的所有「有序對」組成的集合,我們可以把這個集合的元素寫成「方陣」(Square Matrix)的形式,而diag(D2)就是這個方陣的「主對角線」(Main Diagonal)上的元素。舉例說,設D = {a, b, c, d},那麼D2可以表達為下列方陣:
而
D2 − diag(D2) ⊆ LOVE的意思就是,D中每個元素都與所有其他元素存在LOVE的關係,但自己卻不一定與自己存在LOVE關係。
語句(9)的情況比(8)更複雜,因為它牽涉到「傳遞性」(Transitivity)的概念。舉一個簡單例子,設有四本書a、b、c和d,它們以下列方式堆成一疊:
我們定義一個二元關係PILE以刻劃哪本書緊貼在哪本書的上面,那麼有序對(a, b)和(b, c)屬於PILE,但(a, c)卻不屬於PILE。可是根據"on top of"的某種寬鬆語義,語句"a is piled on top of c."卻是真的。為了解決這個矛盾,我們必須引入「傳遞閉包」(Transitive Closure)的概念。簡單地說,二元關係B的「傳遞閉包」B+就是包含B的最小的「傳遞關係」,即若有(a, b) ∈ B ∧ (b, c) ∈ B,則必有(a, c) ∈ B+。這樣,我們便可以用PILE+來刻劃"piled on top of"的概念。現在我們可以把語句(9)的真值條件寫為
在上式中,upper(D2)代表方陣D2中位於「主對角線」及以上的元素。仍以上面的D = {a, b, c, d}為例,那麼
這裡要使用upper(D2),這是因為PILE是不對稱關係,對於任何兩個不相等的元素a和b,我們無需同時考慮(a, b)和(b, a)是否屬於PILE+ (註13)。
我們可以把語句(8)-(9)的真值條件推廣為一般形式。跟前面4.2小節類似,我們只考慮「<1,1>型右遞增量詞」的情況。下表列出兩種「普通相互量詞」的真值條件,這些量詞的類型皆為「<1,2>型量詞」。在下表中,Q、A和B分別為「<1,1>型右遞增量詞」、「一元函項」和「二元關係」:
| 論元結構 | 真值條件 |
|---|---|
「相互代名詞」不僅可以「普通格」(Common Case)的形式出現,也可以「所有格」(即"each other's"和"one another's")的形式出現,例見以下句子:
誠如筆者在上一小節所指出的,「普通相互量詞」可以有多種真值條件。相應地,「領屬相互量詞」(Possessive Reciprocal Quanfitifer)也可以有多種真值條件。為簡化討論,本文只考慮對應著上一小節Crq12(Q)的「領屬相互量詞」。「領屬相互量詞」與「普通相互量詞」的區別在於,「普通相互量詞」描述子集D中每一個元素與其他元素之間的關係,由於發生關係的雙方來自同一個子集D,這種關係可以用D × D (即D2)來表示;「領屬相互量詞」則描述子集D中每一個元素與其他元素的「被領屬者」之間的關係。由於發生關係的雙方並非同屬子集D,這種關係只能用D × E來表示,其中E是由D中元素的「被領屬者」組成的集合。下表列出「被領屬者」為普通名詞和關係名詞的情況下E的集合論表達式:
| 「被領屬者」的語言類型 | 「被領屬者」的形式化表達 | E的集合論表達式 |
|---|---|---|
上表顯示,E的元素不是個體而是集合,這是因為D中每一元素的「被領屬者」可以不只一個事物。舉例說,若D = {a, b, c, d},而「被領屬者」是關係名詞「父親」(以二元關係FATHER代表),那麼
即E是由D中每一元素的父親(請注意「每一元素的父親」本身是一個「單元集」)所組成的集合。
有了以上的定義,我們便可以把語句(10)的真值條件寫為(註14):
在上式中,Prq12代表「領屬相互量詞」,E則是上面(11)所定義的集合。由於E所含元素的數目與D的元素數目相同,D × E可表達為一個「方陣」,所以我們可以定義diag(D × E)。我們還可以把上式推廣到一般情況,詳見下表:
| 量詞類型 | 論元結構 | 真值條件 |
|---|---|---|
其中E = {OWNx ∩ B: x ∈ D} |
||
其中E = {R−1x: x ∈ D} |
筆者以往曾介紹「結構化量詞」作為「單式量詞」和「迭代量詞」的用法,除此以外,「結構化量詞」還可與其他量詞組合成意義複雜的「多式量詞」,這些量詞有些可以表述為「迭代多式量詞」,有些則是「非迭代多式量詞」。以下介紹學界較多研究的幾種「複雜結構化量詞組合」。
「同異比較詞」"(the same)"和"different"可以與其他量詞構成某些複雜結構,試看以下例句:
我們首先把這兩句抽象為以下論元結構:
然後再考察這兩句的真值條件。在語句(12)中,量詞"no"與"boys"中間有一個數詞2,因此該量詞並不直接修飾"boys"。事實上,該句等同於
即"no"實際上是修飾"pair of boys"。現在的問題是如何表達"pair of boys"?由於這裡的"pair"包含無次序和相異的兩個元素,我們可以把"pair of boys"表達為「無序對」,而"no"修飾的對象則是由「無序對」組成的集合。根據此一分析,(12)可以被表達為(在下式中,筆者使用以下簡寫:ANSWERx = {z: ANSWER(x, z)}):
請注意在上式中,"no"的兩個論元都是「無序對集合」,上式的意思是在BOY中沒有任何兩個(不同的)元素,他們所回答的問題是相同的集合。接著我們定義以下集合來代表"answered the same questions":
這個集合就是由那些回答相同問題的「無序對」組成的集合。利用上述集合,我們便可以把(12)表達為以下的「迭代」形式:
語句(13)的情況則較為複雜。首先,到目前為止,筆者還沒有討論「任指量詞」"any"的語義,這是因為這個量詞的語義問題非常複雜,歷來存在很多爭議,它似乎含有多種語義。不過在(13)這類句子中我們可以把這個量詞處理成以「無序對集合」作為修飾對象的「全稱量詞」。其次,正如筆者在《廣義量詞系列:基本單式量詞》所指出的,"different"可以有弱和強兩種意義。仿照(12),我們首先定義以下兩個集合,分別代表弱和強兩種意義下的"dated different girls":
根據上述分析,我們可以把(13)的兩種意義分別表達為以下的「迭代」形式:
我們可以把語句(12)-(13)的真值條件推廣為一般形式,該兩句的論元結構具有以下一般形式:
上式代表一個「<<1,1>,2>型量詞」,其中A和B為「一元函項」,C為「二元函項」,Q為"(any 2)"或"(no 2)",Q'則為"the same"、"differentw"或"differents"。利用與(12)-(13)類似的分析,我們可以把上式的真值條件表達為以下「迭代」形式:
在上式中,Q''是對應於Q的「<1,1>型量詞」,若Q為"(any 2)",則Q''為"every";若Q為"(no 2)",則Q''為"no"。在上式中,Q''是我們熟識的「<1,1>型量詞」,惟有 Q'(B)(C)是筆者以往未曾介紹的新結構,這種結構代表(12)和(13)中的"answered the same questions"和"dated different girls",可以表達為「無序對集合」。下表給出由三個「結構化量詞」構成的Q'(B)(C)的集合論表達式:
| 論元結構 | 集合論表達式 |
|---|---|
除了前述的「二重量詞結構」外,學界還常常談到"(different ... the same)"和"(different ... different)"結構。不過,這兩種結構在語義上其實分別等同於"(any 2 ... the same)"和"(any 2 ... different)"結構,所以無需再作特別介紹。
「結構化量詞」還可以與其他兩個量詞構成複雜的組合,首先考慮以下語句:
請注意上句實際上等同於
由此可見上句其實包含著三重量詞:"(at least 4)"、"(any 2)"和"(the same)"。根據上述分析,我們可以把語句(14)的真值條件表達為:
以上真值條件是說,存在一個BOY的子集D,它包含BOY中至少4個元素,並且D中任何兩個元素所回答的問題都相同,這正是(14)所要表達的意思。以上真值條件亦顯示,(14)中的量詞是「非迭代多式量詞」。理論上,我們還可以把(14)推廣為一般形式,不過由於(14)的量詞是「非迭代多式量詞」,我們必須引入新的「非迭代算子」。由於學界現時還未對這類「非迭代多式量詞」作系統研究,所以這裡不擬深入探討這個問題。
接著考察以下含有「從屬分句」(Dependent Clause)的複雜句:
請注意上句實際上等同於
根據以上分析,我們可以把上句抽象為以下論元結構:
請注意儘管(15)在形式上"some teacher"是位於"more girls"之後,但在論元結構上"some teacher"卻應在"more girls"之前。以下是(15)的真值條件(下式使用了簡寫:KNOWx = {z: KNOW(x, z)}):
接著我們定義以下集合來代表"knows more girls than":
上述集合是由「有序對」(x, y)組成的集合,其中x比y認識較多女孩。請注意由於在"x knows more girls than y"中x和y的地位是不對稱的,所以把"knows more girls than"表達為「有序對的集合」較為恰當。利用上述集合,我們便可以把(15)表達為以下的「迭代」形式:
讀者可自行驗證,對上式進行「迭代」運算,我們可以得到前述的真值條件。
我們還可以把(15)推廣為一般情況,該句的論元結構具有以下一般形式:
上式代表一個「<<1,1,1>,2>型量詞」,其中Q和Q'為「<1,1>型量詞」,Q''為「結構化量詞」,A、B和C為「一元函項」,D為「二元函項」。利用與(15)類似的分析,我們可以把上式的真值條件表達為以下「迭代」形式:
在上式中,Q和Q'都是我們熟識的「<1,1>型量詞」,惟有Q''(C)(D)是筆者以往未曾介紹的新結構,這種結構代表(15)中的"knows more girls than",可以表達為「有序對的集合」。下表給出由各種「結構化量詞」構成的Q''(C)(D)的集合論表達式:
| 論元結構 | 集合論表達式 |
|---|---|
筆者在《廣義量詞系列:量詞的迭代運算》中介紹了「格擴充算子」的概念,可用來推導很多「迭代量詞」的真值條件。可是,在自然語言中,還存在某些不屬量詞的「格擴充算子」。以下介紹這些特殊的「格擴充算子」。
在自然語言中,「反身代名詞」(Reflexive Pronoun)的主要語法功能是表達某一句子成分與句中另一成分有相同的所指(簡稱「同指」Co-reference),例如在語句
中,「反身代名詞」"himself"與主語"John"同指。由於「反身代名詞」的一般語法功能類似一個名詞短語,我們可以把「反身代名詞」處理成一種特殊的「格擴充算子」,以下稱為「普通反身化算子」(Common Reflexivization),記作selfi,這裡的下標i代表「反身代名詞」與句子的第i論元同指。以下是selfi的真值條件。設F(x1 ... xn+1)為n + 1元函項,則有:
selfi雖然不是量詞,但由於其外形近似英語中的「反身代名詞」,所以在上式中筆者把它當作普通的「<−,1>型量詞」寫成selfi(−)的形式。上式顯示,把[selfi(−)]j (其中i > j)(註15)作用於F後,所得結果為一個n元函項,並且使F的第j個論元與第i個論元同指。利用上式以及「迭代」運算,我們可以推導語句(16)的真值條件(細節從略):
「反身代名詞」除了以單純形式出現外,亦可與其他詞項組成複合形式,例見以下三句:
為此,我們定義以下三個更複雜的「普通反身化算子」:
舉例說,利用上面第二式,可以求得語句(17)的真值條件為:
容易驗證,上式所表達的正是語句(17)的意思。
正如「相互代名詞」一樣,「反身代名詞」也有「所有格」形式。不過,英語並無"*himself's"、"*herself's"等形式。在英語中,如要表達含領屬意義的「反身代名詞」,只需使用普通的「所有格代名詞」。有時為了強調領屬意義,可以加用一個形容詞"own",例見以下句子:
十分有趣的是,這個形容詞"own"正可譯成漢語的「自己的」,跟漢語的一般「反身代名詞」具有相同的形式。為此,我們引入一個「領屬反身化算子」(Possessive Reflexivization),記作owni。下表列出「領屬反身化算子」的兩種真值條件。在下表中,A為普通名詞(即一元函項),R為關係名詞(即二元函項),F(x1 ... xn+1)為n + 1元函項。
| 論元結構 | 真值條件 |
|---|---|
在上表中筆者把owni當作「<1,1>型量詞」(與普通名詞連用時)或「<2,1>型量詞」(與關係名詞連用時)寫成owni(A)或owni(R)的形式。上表顯示,把[owni(A)]j或[owni(R)]j (其中i > j)作用於F後,所得結果為一個n元函項,並且使F的第j個論元變成A ∩ OWNyi或R−1yi。利用上表第二行以及「迭代」運算,我們可以推導語句(18)的真值條件(細節從略):
容易驗證,上式所表達的正是語句(18)的意思。正如「普通反身化算子」一樣,「領屬反身化算子」亦可與其他詞項組成類似上一小節所述的複合形式,這裡不擬深入討論。
從邏輯上說,「反身代名詞」類似一個「約束變項」(Bound Variable)。舉例說,語句"Everybody loves himself."在一階謂詞邏輯中可以表達為
在上式中,「反身代名詞」"himself"被表達為受全稱量詞「∀」約束的變項x。在自然語言中,除了「反身代名詞」外,很多代名詞其實都起著「約束變項」的作用。試看以下語句:
在上面第一句中,如果我們把"he"理解成與"everybody"同指,那麼這個"he"便起著「約束變項」的作用,跟「反身代名詞」非常相似,所不同者是該句的"he"充當分句中的主語,而「反身代名詞」則不能充當主語。上面第二句則是語言學上有名的「巴赫-彼得斯句式」(Bach-Peters Sentences)的一種表現形式。該句的特點是第一和第二個關係分句中的代名詞"it"和"him"分別與第二和第一個量詞"exactly one Mig"和"each pilot"同指,形成一種特殊的「交叉約束」關係。由於普通代名詞不像「反身代名詞」那樣有明顯的形式標記,我們只能根據句意判斷普通代名詞是否起著「約束變項」的作用,因此本文不擬詳細討論普通代名詞充當「約束變項」的問題。
在自然語言中,有兩種典型的「非及物化」操作可以令二元或更高元謂詞減元,這兩種操作分別為「主格-賓格」(Nominative-Accusative)語言中的「被動態」(Passive Voice)以及「作格-絕對格」(Ergative-Absolutive)語言中的「反被動態」(Anti-Passive Voice)。「主格-賓格」語言和「作格-絕對格」語言是世界上的兩大語言類型,前者包括英語、法語、西班牙語等大多數語言,在這類語言中,不及物動詞的主語與及物動詞的主語採取相同的形式(「主格」),而及物動詞的賓語則採取另一種形式(「賓格」),而且「主格」比「賓格」具有較「基本」的地位;後者則包括柏柏爾語(Berber)、愛斯基摩語(Eskimo)以及中美洲和太平洋某些土著語言,在這類語言中,不及物動詞的主語與及物動詞的賓語採取相同的形式(「絕對格」),而及物動詞的主語則採取另一種形式(「作格」),而且「絕對格」比「作格」具有較「基本」的地位。
由於存在以上差異,上述兩大語言類型的「非及物化」操作也各具特色。先看英語「被動態」的例子:
其次看格陵蘭愛斯基摩語「反被動態」的例子:
上述兩種操作雖然各有不同,但也有一個共同點,就是兩種操作都把原來具有基本地位的名詞短語「邊緣化」(即變為「介詞賓語」或「非核心格」Non-Core Case,例如「工具格」Instrumental Case名詞),而原來處於次要地位的名詞短語則取得基本地位。例如,在上述兩個例子中,原來具有基本地位的「主格」名詞"I"和「絕對格」名詞"niqi"都被「邊緣化」,而原來處於次要地位的「賓格」名詞"him"和「作格」名詞"arnap"則分別變成「主格」和「絕對格」名詞,從而取得基本地位。請注意由於被「邊緣化」後的名詞常可被略去,上述兩種操作使原來的「及物句」變成「不及物句」,從而達到「減元」的效果。
為了統一表達上述兩種操作,我們可以定義一個「非及物化算子」(Detransitivization)。設F(x1 ... xn+1)為n + 1元謂詞,則有
在上式中,算子Dtsi的下標i代表F的第i論元被「邊緣化」,因而所得結果為一個n元函項。利用上述定義,我們可以把上面的「被動態」動詞"was hurt"和「反被動態」動詞"nirinnigpuq"分別表達為:
利用「迭代」運算,我們可以推導以上兩個「不及物句」(假設略去「邊緣化名詞」)的真值條件(註16):
我們還可以把上述的「非及物化算子」擴大應用於解釋自然語言中的某些省略現象。舉例說,漢語經常出現省略動詞的某些論元的情況,例如語句「他吃了」便省略了賓語。請注意在這種省略句中,被省略的論元雖然沒有出現,但在語義上卻是隱含著的。因此我們不妨把這種現象看成「非及物化算子」的應用,把這句中的「吃了」表達為Dts2(EAT)。
除了上述「非及物化算子」外,在自然語言中還有其他「減元」操作。舉例說,在英語中,"break"本來是二元謂詞,但有時卻可像一元謂詞那樣只需一個主語,例見以下句子:
請注意上句並不等同於「被動句」"The glass was broken.",這是因為上句不像「被動句」那樣隱含著「施事」名詞。為此,我們要引入一種有別於「非及物化算子」的「減元」算子。Dixon和Aikhenvald在Changing Valency - Case Studies in Transitivity一書中把上述這種現象稱為「反使役」(Anti-Causative)操作(註17)。為此,我們可以定義一種「反使役化算子」(Anti-Causativization) Acs1,並把上句中的"broke"表達為Acs1(BREAK)。請注意這種算子實際是透過取消二元函項BREAK的第一論元而把它變成一個一元函項。由於它所產生的是一個論元結構全新的函項,我們不能透過原來的函項BREAK來定義新的函項Acs1(BREAK),但可以規定以下的「意義公設」以表達「被動句」與「反使役句」的蘊涵關係。設Q、A和F分別為「<1,1>型量詞」、一元函項和二元函項,則有
上式其實反映了以下蘊涵關係:
Dixon和Aikhenvald還討論了某些語言的「反身/相互」操作,這種操作有兩種主要形式:第一種形式是以「反身/相互代名詞」佔去謂詞的其中一個論元位置,第二種形式則是以某種動詞「詞綴」(Affix)使及物動詞變成減去一元的「反身化/相互化動詞」。舉例說,北美洲的土著霍皮語(Hopi)便有一個「反身化」前綴"naa-",把這個前綴加到動詞"tiwa"(「看見」)前,便得到「反身化動詞」"naatiwa"(「看見自己」)。其實如果我們把這些前綴看成附在動詞上的「反身/相互代名詞」,那麼上述兩種「反身/相互」操作便沒有實質區別。
關於「反身/相互代名詞」,筆者在上文已作了詳細討論。不過,在自然語言的某些語句中,「反身/相互代名詞」的意義非常虛無。試看以下法語句子:
在上句中,「反身代名詞」"se"幾乎沒有意義。事實上,從上句的漢譯可以看到,上句在語義上較接近前述的「反使役句」,即及物動詞"vend"已蛻變為一個不及物動詞,而上句的主語"le livre"在相應的「及物主動句」中本應作為"vend"的賓語。由此可見,「反身/相互」操作與「反使役」操作之間存在交叉重疊的關係(註18)。由於這涉及到較複雜的理論問題,本文不再深入討論。
除了「減元」操作外,Dixon和Aikhenvald還討論了兩種「增元」操作,即「使役」(Causative)操作和「施動」(Applicative)操作。這兩種操作的共同點是都可令謂詞增加一個論元,但兩者又各有不同。「使役」操作的特點是新增的論元佔去第一論元的位置,而原句中的第一論元則退居較後的論元位置;「施動」操作的特點則是原句中的第一論元保持於原位不動,而新增的論元佔據其後的某個論元位置。試比較以下英語的「使役句」和中美洲土著薩波特克語(Zapotec)的「施動句」:
有些人可能覺得似乎應把上述英語「使役句」處理成含有兩個動詞的複雜句,但如果我們把"make"看作語義虛無的「使役助動詞」,那麼它的語法功能便跟薩波特克語中的「施動後綴」"-nee"非常相似,這樣上述兩個例子便有相通之處。為了統一表達上述兩種操作,我們可以定義一個「及物化算子」(Transitivization) Tsti。這種算子的作用是使原來的函項增加一個論元,並使這個新增論元作 為新函項的第i論元。舉例說,上述兩句中的"made ... work"和"biillynee"便可以分別表達為Tst1(WORK)和Tst2(SING)。跟上一小節相似,「及物化算子」產生的是一個論元結構全新的函項,因此我們不能透過原來的函項WORK和SING來定義新的函項Tst1(WORK)和Tst2(SING),但可以規定以下的「意義公設」以表達某種蘊涵關係。設Q和Q'為「<1,1>型量詞」,A和B為一元函項,F為二元函項,則有
以上兩式其實反映了以下蘊涵關係:
筆者至今已介紹了語言學界所關注的眾多「單式量詞」和「多式量詞」。不過,這些量詞只佔邏輯上可能存在的量詞的極小部分。事實上,根據某些學者的計算,邏輯上可能存在的「<1,1>型量詞」的總數為2x,其中x = 4|U|,|U|代表論域中個體的總數。舉例說,對於一個只有兩個個體的小型論域而言(即|U| = 2),x = 42 = 16,而邏輯上可能存在的「<1,1>型量詞」的總數卻多達
216 = 65536個。為何語言學界只研究這眾多量詞中的一小部分?這是因為在自然語言中真實存在的量詞只佔邏輯上可能存在的量詞的極少數。
不過,由於量詞與數學或邏輯學有密切的關係,某些在自然語言中不存在的量詞,由於具有理論意義,卻成為數學或邏輯學的研究對象。下表列出部分具有數學或邏輯學理論意義的量詞。在下表中,A和B為個體集合,p / q為小於1的有理數,R為n元組集合,x和y為普通個體變項,f和g為把U映射到U的函數變項。
| 量詞類型 | 論元結構 | 真值條件 |
|---|---|---|
上表首兩行的兩個量詞稱為「平凡量詞」(Trivial Quantifier),它們分別代表對任何論元A恆取真值和假值的量詞,它們的真值條件A = A和A ≠ A分別代表在邏輯上恆真的「重言式」(Tautology)和恆假的「矛盾式」(Contradiction)。請注意我們可以把這兩個<−,1>型量詞推廣為其他類型的「平凡量詞」,例如我們可以定義以下兩個「平凡<1,1>型量詞」
即對任何集合A、B,前者恆取真值,後者恆取假值。上表中的其他量詞在數學或邏輯學上都有某種理論意義,這裡不擬一一介紹。
註1:形式語義學界對量詞"Any"的語義解釋有極大爭議,有些人認為它是一種具有全稱語義的「自由選項詞」(Free Choice Item),有些人則認為它是具有存在語義的「負極性詞」(Negative Polarity Item),亦有人認為它兼有兩種語義。就語句(1)而言,把"any"處理成「負極性詞」是合理的,因此可以把它處理成等同於"some"。

