
「博奕論」(Game Theory)是在當代發展起來的應用數學學科,在多個學科領域中都有應用。一場「博奕」(Game)包含以下因素:一組「對奕者」(Player),這些「對奕者」所能採取的「行動」(Move)或「策略」(Strategy),以及各種「行動」組合所引致的「賽果」(Payoff),此一「賽果」可以採取勝負或分數的形式。
當代的數理邏輯也有應用博奕論的理論和方法,廣義量詞理論作為數理邏輯的引申,因此也用得上博奕論。本文將介紹博奕論在廣義量詞理論上的兩種應用,這兩種應用分別對應著兩類博奕-「公式博奕」和「結構博奕」,從前者我們可以推導出「博奕論語義學」,這是對量詞語義的一種特殊解釋方法;從後者我們可以推導出邏輯不可定義性的一種簡便證明方法。
「公式博奕」(Formula Game)是指以邏輯公式為博奕對象的博奕,最簡單的「公式博奕」以「命題邏輯」公式為博奕對象,這種博奕在「計算複雜性理論」中也有所研究。本節要介紹的博奕是以「謂詞邏輯」公式作為博奕對象,Hintikka、Kulas、Sandu等人把這種博奕應用於經典量詞(即"∀"和"∃")的語義解釋,從而開創了「博奕論語義學」(Game-Theoretic Semantics),本小節介紹這方面的基礎知識。
給定一個謂詞邏輯的命題S和語義模型M,我們可以把根據M判定S真假的過程看成兩名對奕者之間的博奕,記作G(S, M)。這兩名對奕者在開始時分別充當「證實者」(Verifier)(記作V)和「證偽者」(Falsifier)(記作F)的角色,V和F的任務分別為證明S真和S假。博奕的規則是根據S的形式確定V或F可採取甚麼行動,以下是有關規則:
| 規則 | S的形式 | 行動 |
|---|---|---|
| 若S在M中真,則V勝F負;若S在M中假,則F勝V負。 | ||
| 兩名對奕者對調角色,然後繼續進行G(S0, M)。 | ||
| F選擇i = 1或2,然後繼續進行G(Si, M)。 | ||
| V選擇i = 1或2,然後繼續進行G(Si, M)。 | ||
| F在M的論域U中選擇一個個體a,然後繼續進行G(S0[a/x], M)。 | ||
| V在M的論域U中選擇一個個體a,然後繼續進行G(S0[a/x], M)。 |
在上表中,S0[a/x]代表用常項a代替命題S0中所有變項x。利用上表,我們可以把S逐步化簡至原子公式,然後根據規則1判斷誰勝誰負。在開始時,若V有必勝策略,則S真;若F有必勝策略,則S假,而S的真值條件就體現在V和F的必勝策略中。
以下用一個例子來說明上述概念,設我們有命題(註1)
以及語義模型M1:
BOY = {a, b}, GIRL = {c, d}, LOVE = {(a, a), (a, c), (b, d), (c, b), (c, c)} |
為應用表1的規則,我們須先把(1)改寫為以下等價形式:
在上述語義模型M1下,V可按以下策略進行博奕。設在開始進行G(S1, M1)時,F根據規則5,在U中選擇一個屬BOY的個體,例如a,然後繼續進行G(S2, M1),其中
接著V便可根據規則6,選擇一個屬GIRL但不為a所愛的個體,例如d,然後繼續進行G(S3, M1),其中
接著V根據規則4,在(4)的兩個析取項中選擇~LOVE(a, d),然後繼續進行G(~LOVE(a, d), M1)。接著根據規則2,V與F對調角色,並繼續進行G(LOVE(a, d), M1)。最後根據規則1,由於原子公式LOVE(a, d)在M1中假,所以F (即最初的V)勝。
假如在開始進行G(S1, M1)時,F根據規則5,選擇一個不屬BOY的個體,例如c,那麼V便可根據規則6,任選一個個體,例如c。接下來的博奕將是G(S4, M1),其中
接著V根據規則4,在(5)中選擇~(BOY(c) ∧ GIRL(c))。接著根據規則2,V與F對調角色,並繼續進行G(BOY(c) ∧ GIRL(c), M1)。接著F (即原來的V)可根據規則3,選擇BOY(c)。最後根據規則1,由於BOY(c)在M1中假,F (即最初的V)勝。
上述討論顯示,不論在開始時F選擇屬BOY還是不屬BOY的個體,V最終都能勝出。當然,V可能由於對奕策略不當而落敗,例如假設博奕進行至上述G(S4, M1)的情況,而V根據規則4,在(5)中選擇~LOVE(c, c)。接著根據規則2,V與F對調角色,並繼續進行G(LOVE(c, c), M1)。這時由於原子公式LOVE(c, c)在M1中真,根據規則1,V (即最初的F)勝,而F (即最初的V)負。可是,如果我們假設兩名對奕者都是有理性且懂得運用最佳策略的人,上述情況便可排除。事實上,在上述假設下,賽果在博奕開始前便已確定了,即V必勝F必負。
由此可見,我們關心的不是某一場博奕的勝負,而是對奕者何方有必勝策略。根據上述討論,我們知道在對(1)的博奕中,V有必勝策略當且僅當對U中每一個男孩x,都有至少一個女孩y,使得~LOVE(x, y),但這正是(1)的真值條件。由此我們把經典量詞的語義解釋問題轉化為二人博奕的問題,這就是「博奕論語義學」的精神所在。
謂詞邏輯除了常見的「非限制型量化」形式外,還有一種「限制型量化」形式,這兩種形式的區別體現在命題「所有A是B」的以下兩種翻譯:
上面的(6)和(7)分別為「非限制型量化」和「限制型量化」形式,前者以整個論域U作為量化範圍,後者以U中某個集合A作為量化範圍,請注意「限制型量化」較貼近自然語言的量化特點。由於表1規則5和6中的S是「非限制型量化」表達式,如把S改為「限制型量化」形式,我們便要把該兩條規則改為:
| F在集合A中選擇一個個體a,然後繼續進行G(S0[a/x], M)。 | ||
| V在集合A中選擇一個個體a,然後繼續進行G(S0[a/x], M)。 |
Hintikka等人開創的「博奕論語義學」,除了用來解釋謂詞邏輯公式的語義外,也用來解釋自然語言量化句的語義。因此除了表1的規則外,他們也為自然語言的邏輯聯結詞(例如"and"、"or"等)、量詞(例如"every"、"some"等)設計了相應的博奕規則,而且他們的規則是建基於自然語言的句子形式而非邏輯表達式,下表是有關"every"和"some"的規則(下表略去了「原子句子」、否定(以"~"表示)、"and"和"or"的規則,這是因為這些規則跟表1的相應規則大同小異):
| 規則 | S的形式 | 行動 |
|---|---|---|
| F在集合A中選擇一個個體x,然後繼續進行G("X x Y", M)。 | ||
| V在集合A中選擇一個個體x,然後繼續進行G("X x Y", M)。 |
在上表中,"every A"和"some A"代表帶有限定詞的名詞短語,其中A代表普通名詞短語,但為了方便下文的推導,這裡把A視作集合;"X"和"Y"則代表與"every A"或"some A"處於同一句中的其他語言成分(可空),這裡寫成這種抽象形式,是因為名詞短語"every A"和"some A"可以出現於多種句法位置(主語、賓語等)。請注意上表的規則跟前述「限制型量化」表達式的博奕規則非常相似(註2)。至於其餘兩個常用量詞"no"和"not every",它們可以分別看成"some"和"every"的否定,例如設博奕進行至G("X no A Y", M),我們可以隨即把它轉化為G("X ~some A Y", M),然後繼續應用規則2和規則6分兩步處理。
繼Hintikka等人之後,某些學者進一步發展「博奕論語義學」,把博奕概念推廣應用於廣義量詞的語義解釋,例如Clark的Quantifier Games and Reference Tracking以及Pietarinen的Most Even Budged Yet: Some Cases for Game-Theoretic Semantics in Natural Language便為多種類型的廣義量詞提出了博奕模型,以下抽選Clark和Pietarinen的一些研究成果作出介紹(加上筆者的一些修補)(註3)。
我們首先從限定詞開始。絕對數量比較詞(例如"at least n"、"more than n"等)是除了經典量詞以外最簡單的限定詞,以下是它們的博奕規則(作為表2的補充):
| V在集合A中選擇一個子集A'使得|A'| ≥ n,然後繼續進行G("X every A' Y", M)。 | ||
| V在集合A中選擇一個子集A'使得|A'| > n,然後繼續進行G("X every A' Y", M)。 |
規則7的理據是,三分結構式"(at least n)(A)(B)"可以表達為以下高階邏輯表達式:
請注意上式所包含的全稱量詞"∀"顯示"at least n"這個限定詞的語義含有「逐指性」(Distributivity)。
至於"at most n"和"fewer than n",我們可以把它們分別處理成"more than n"和"at least n"的否定(註4);而"between m and n"則可以處理成上述限定詞的合取,例如設博奕進行至G("X between m and n A Y", M),我們可以隨即把它轉化為G("X at least m A Y and X at most n A Y", M)。
在絕對數量比較詞中,"exactly n"和"all except n"表達等同關係,因此其博奕規則為:
| V在集合A中選擇一個子集A'使得|A'| = n,然後繼續進行G("X every A' Y and X no (A − A') Y", M)。 | ||
| V在集合A中選擇一個子集A'使得|A'| = n,然後繼續進行G("X no A' Y and every (A − A') Y", M)。 |
規則9的理據是,三分結構式"(exactly n)(A)(B)"可以表達為以下邏輯表達式:
上式最外層括號中的部分表示
由於A'是A的子集,上式實際等同於A' = A ∩ B,請參見下圖:
由於例外量詞"no ... except John"和"all ... except John"也是表達等同關係,我們可以用類似規則9和10的方法來處理這兩個量詞,例如設博奕進行至G("X no A except j Y", M),我們可以隨即把它轉化為G("j is an A and X j Y and X no (A − {j}) Y", M)。
接著討論相對數量比較詞(例如"at least q"、"more than q"等),筆者在《廣義量詞系列:量詞的邏輯性質》中曾指出,上述這些限定詞是一階不可定義的,但在博奕論語義學中,我們假設對奕者擁有有關|A|的資料,因此容易得到這些限定詞的博奕規則:
| V在集合A中選擇一個子集A'使得|A'| / |A| ≥ q,然後繼續進行G("X every A' Y", M)。 | ||
| V在集合A中選擇一個子集A'使得|A'| / |A| > q,然後繼續進行G("X every A' Y", M)。 | ||
| V在集合A中選擇一個子集A'使得|A'| / |A| = q,然後繼續進行G("X every A' Y and X no (A − A') Y", M)。 | ||
| V在集合A中選擇一個子集A'使得|A'| / |A| = q,然後繼續進行G("X no A' Y and every (A − A') Y", M)。 |
其他相對數量比較詞可以由以上規則定義,例如"most"便等同於"more than 1/2","at most q"和"less than q"則分別等於"more than q"和"at least q"的否定。
除了上述限定詞外,廣義量詞理論還有研究各種「有定限定詞」(例如"the"、"John's"等)和「部分格結構」(例如"all of the n"、"exactly m of the n"等),由於這些限定詞的真值條件涉及語境集X/集合OWNj以及預設,它們的博奕規則也相應地較為複雜,因此本文不擬介紹。
本小節只討論「第一類結構化量詞」(例如"more ... than ..."、"at least n more ... than ..."等)和「第二類結構化量詞」(例如"the same ... as ..."、"differentw ... than ..."等),以下首先提供部分「<12,1>型第一類結構化量詞」的博奕規則:
| V選擇一個自然數k,然後繼續進行G("X at least (k + n) A Y and X at most k B Y", M)。 | ||
| V選擇一個自然數k,然後繼續進行G("X exactly (k + n) A Y and X exactly k B Y", M)。 | ||
| V選擇一個自然數k,然後繼續進行G("X at least nk A Y and X at most k B Y", M)。 | ||
| V選擇一個自然數k,然後繼續進行G("X exactly nk A Y and X exactly k B Y", M)。 | ||
| V選擇一個自然數k,然後繼續進行G("X at least (1 + q)k A Y and X at most k B Y", M)。 | ||
| V選擇一個自然數k,然後繼續進行G("X exactly (1 + q)k A Y and X exactly k B Y", M)。 | ||
| V選擇一個有理數q (0 < q < 1),然後繼續進行G("X more than q A Y and X at most q B Y", M)。 | ||
| V選擇一個有理數q (0 < q < 1),然後繼續進行G("X at least q A Y and X at most q B Y", M)。 | ||
| V選擇一個有理數q (0 < q < 1),然後繼續進行G("X exactly q A Y and X exactly q B Y", M)。 |
其他「第一類結構化量詞」可以由以上規則定義,例如"more A than B"和"at least as many A as B"便分別等同於"at least 1 more A than B"和"at least 0 more A than B";"at least n fewer A than B"等同於"at least n more B than A";"at least q less A than B"等同於"at least q / (1 − q) more B than A" (註5)等等。
只要對上表的規則作適當修改,便可把這些規則應用於其他類型的「第一類結構化量詞」。以語句"At least 3 more boys sang than danced"為例,這句涉及「<1,12>型第一類結構化量詞」,其抽象形式為
其中A和B代表動詞短語,Z則是代表任意名詞短語。把上式跟規則15比較,容易看到上述「<1,12>型第一類結構化量詞」的博奕規則應為
「第二類結構化量詞」全都具有「<1,12>」的類型,以下是這些量詞的博奕規則:
| V在集合A和B中各選擇一個子集A'和B'使得A' = B',然後繼續進行G("every A' is a Z and no (A − A') is a Z and every B' is a Z and no (B − B') is a Z", M)。 | ||
| V在集合A和B中各選擇一個子集A'和B'使得A' ≠ B',然後繼續進行G("every A' is a Z and no (A − A') is a Z and every B' is a Z and no (B − B') is a Z", M)。 | ||
| V在集合A和B中各選擇一個子集A'和B'使得A' ∩ B' = Φ,然後繼續進行G("every A' is a Z and no (A − A') is a Z and every B' is a Z and no (B − B') is a Z", M)。 | ||
| V在集合A和B中各選擇一個子集A'和B'使得A' ⊆ B',然後繼續進行G("every A' is a Z and no (A − A') is a Z and every B' is a Z and no (B − B') is a Z", M)。 |
請注意上面區分了"different"的強、弱兩種意思,分別以下標"s"和"w"代表。
迭代量詞是由多個單式量詞經迭代運算構成的,筆者在《廣義量詞系列:量詞的迭代運算》中詳細介紹了廣義量詞理論推導迭代量詞的方法。但在博奕論語義學下,我們卻無需進行這種推導,這是因為博奕論語義學的實質是以論域中的個體取代句子中的每個量化短語,最後化歸為只包含謂詞和個體的「原子句子」。不過,由於自然語言的量化句可能有「轄域歧義」的問題,為了消解歧義,我們須先對處於較寬域的量化短語應用博奕規則。以下用一個例子以作說明,設我們有句子
以及語義模型M2:
TEACHER = {g, h, i, j}, BOY = {a, b}, GIRL = {c, d, e, f} RECOMMEND = {(g, a), (g, c), (h, b), (i, b), (i, e), (i, f), (j, a), (j, b), (j, d), (j, e)} |
我們並假設在(11)中,"all except 2 teachers"取寬域。為應用上述博奕規則,我們首先把(11)改寫為以下抽象形式:
現在讓我們對(12)進行博奕,由於這句在M2下是假的,可知F有必勝策略。舉例說,設在開始時,根據規則10,V在集合TEACHER中選擇一個子集A'使得|A'| = 2,設為{g, h},然後繼續進行G(S6, M2),其中
這時F可根據規則3選擇S6的以下合取肢:
然後繼續進行G(S7, M2)。接著F可根據規則5,在集合TEACHER − {g, h}中選擇一個個體,設為j,然後繼續進行G(S8, M2),其中
根據2.2.2小節的討論,上式等同於
接著根據規則15,V選擇一個自然數,設為1,然後繼續進行G(S9, M2),其中
這時F根據規則3選擇S9的以下合取肢:
然後繼續進行G(S10, M2)。根據2.2.1小節的討論,上式等同於
根據規則2,V和F對調角色,並繼續進行G("j RECOMMEND more than 1 BOY", M2)。接著根據規則8,V在集合BOY中選擇一個子集A'使得|A'| > 1,設為{a, b},然後繼續進行G("j RECOMMEND every {a, b}", M2)。接著F根據規則5,在{a, b}中選擇一個個體,設為a,然後繼續進行G("j RECOMMEND a", M2)。由於"j RECOMMEND a"是一個「原子句子」,並且其等價表達式RECOMMEND(j, a)在M2中真,根據規則1,V (即原來的F)勝。
筆者在《廣義量詞系列:非迭代多式量詞》中介紹了「概括量詞」,指出這種量詞跟單式量詞的差別僅在於,後者以「個體集合」為論元,而前者則以「n元組集合」為論元。因此之故,概括量詞可以沿用前述單式量詞的博奕規則,只需把前述的「(個體)集合」改為「n元組集合」便可以了。舉例說,由於句子
在邏輯上等同於
我們可以把(20)寫成以下形式:
其中STUDENT2和WAIT-FOR分別代表由所有「學生有序對」和「等候者-被等候者有序對」組成的集合,接著便可應用前述有關"X no A except j Y"的博奕規則來對(22)進行博奕。
上述網頁還介紹了某些「複雜結構化量詞組合」,這些量詞的特點是可以表達為單式量詞與某些「有/無序對集合」進行迭代的結果,不過這些「有/無序對集合」的內容往往依賴於同句中其他量化短語。試考慮以下兩句:
根據上述網頁,(23)和(24)在邏輯上分別等同於(註6)
據此,我們可以把(23)和(24)分別改寫成以下抽象形式:
請注意在(27)中,{{x, y}: BOY(x) ∧ BOY(y)}代表由「無序對」{x, y}組成的集合,其中x和y都屬於BOY;ANSWERED-BY-x和ANSWERED-BY-y這兩個集合則是可變的,須視乎變項x和y取甚麼值。但當V (即原來的F)根據規則6從{{x, y}: BOY(x) ∧ BOY(y)}中選定一個「無序對」後,x和y的值便確定下來,從而也就確定了ANSWERED-BY-x和ANSWERED-BY-y的元素,接下來便可根據規則24繼續進行博奕。
類似地,在(28)中,KNOWN-BY-x和KNOWN-BY-y這兩個集合也是可變的。但當F和V先後根據規則5和6分別選定{x: BOY(x)}和{y: TEACHER(y)}中各一個元素後,x和y的值便確定下來(這個過程相當於確定一個「有序對」(x, y))(註7),從而也就確定了KNOWN-BY-x和KNOWN-BY-y的元素,接下來便可根據規則15繼續進行博奕(把規則15中的n定為1)。
「分枝量詞」與前述「迭代量詞」的區別在於,後者的各個量化短語處於同一條直線上(故又稱「線性量詞」),互有統屬關係,處於窄域的量化短語隸屬於處於寬域的量化短語;前者的各個量化短語則處於不同分枝,不同分枝上的量化短語互相獨立(故又稱「獨立量詞」),互不隸屬,這裡「A隸屬B」的意思是A的語義所指依賴於B的語義所指。舉例說,
就是典型的「迭代量化句」,其中"girl"的語義所指依賴於"boy",因為每名男孩所愛的女孩可能各有不同。反之(本文把下句中的"two"和"four of the"分別當作"exactly two"和"exactly four"處理),
則可被理解成「分枝量化句」,其中"students"與"exams"的語義所指互相獨立,即兩名學生所通過的是相同的四場考試,而通過四場考試的是相同的兩位學生,此一情況可以用下圖來表示(其中S和E分別代表「學生」和「考試」,箭頭代表「通過」):

博奕論語義學從資訊量的角度來刻劃「線性量詞」與「分枝量詞」的差別,前述有關「線性量詞」的博奕規則假設兩名對奕者在進行博奕的整個過程中,都對此前己方和他方的博奕結果有完全的資訊。以(29)的博奕為例,設這句在某語義模型中是真的,當F在模型中選定一名男孩x後,V必須知道F選了x,從而在模型中選出一名為x愛的女孩y,使得LOVE(x, y)真,這樣才能保證V必勝。
跟「線性量詞」不同,「分枝量詞」的博奕規則假設兩名對奕者對己方此前的博奕結果有完全的資訊;至於他方,則只對在同一分枝上的博奕結果有完全的資訊,對其他分枝上他方的博奕結果則全無資訊。以(30)為例,根據Westerstahl的Branching Generalized Quantifiers and Natural Language一文,我們可以把(30)寫成以下抽象形式:
| exactly 2 {x: STUDENT(x)} | x PASS y (31) |
| exactly 4 {y: EXAM(y)} |
在上式中,量化短語"exactly 2 {x: STUDENT(x)}"和"exactly 4 {y: EXAM(y)}"被置於上、下兩個不同分枝,代表這兩個短語各自獨立。設在開始博奕時,兩名對奕者先後根據規則9、規則3、規則5對上一分枝進行博奕,使上式變成:
| j | j PASS y (32) |
| exactly 4 {y: EXAM(y)} |
其中j是F在{x: STUDENT(x)}的某個子集S'中選擇的個體。接下來兩名對奕者對下一分枝進行博奕,根據規則9,V應在{y: EXAM(y)}中選擇一個子集E'。請注意這時V對上一分枝F的博奕結果毫無資訊,即他不知道上一分枝已變成j,因此他接下來所選擇的E'並不依賴於j。由此可以推斷,若果V有必勝策略,情況只能是這樣:S'中任一成員所通過的都是相同的四場考試,而且正就是E'的成員;通過E'中任一成員的都是相同的兩名學生,而且正就是S'的成員(其中一個就是j),而這正是前述(30)的意思。由此可見,前述有關分枝量化博奕的假設正好反映了分枝量化的特點。
上述分枝量化博奕的假設也顯示了某些量化句在線性量化和分枝量化下是等價的,以下句為例:
對上句來說,以下兩種抽象表達式是等價的:
| some {x: GIRL(x)} | x LOVE y (35) |
| some {y: BOY(y)} |
這是因為根據規則6,不論是對(34)還是對(35)進行博奕,都只有V在選擇個體,F由始至終都沒有作出任何選擇,根本不存在F先前的博奕結果,因此(34)和(35)的博奕沒有分別。
接著討論「累指量詞」,請先看以下例句:
對上句的通常理解,既非八名主考員各自會見了100名考生(即共有800名考生,這是「線性量化」),也非八名主考員中的每一人都會見了100名考生中的每一人(這是「分枝量化」),而很可能是籠統地說出「會見」這個行為共涉及八名主考員和100名考生,而沒有交代每名主考員會見了多少名考生,以及每名考生被多少名主考員會見,我們把這種解讀稱為「累指量化」。Sher在Ways of Branching Quantifiers一文中指出可以把「累指量化」看成一種特殊的「分枝量化」,根據Sher的分析,我們可以把(36)寫成以下抽象形式:
| exactly 8 {x: EXAMINER(x)} | x INTERVIEW some C' and some E' INTERVIEW y (37) |
| exactly 100 {y: CANDIDATE(y)} |
在上式中,E'和C'分別代表V根據規則9而選擇的{x: EXAMINER(x)}和{y: CANDIDATE(y)}的子集。
「結構博奕」(Structure Game)以邏輯結構作為博奕對象,最初由Ehrenfeucht和Fraisse提出。在開始介紹「結構博奕」前,我們須先引入數理邏輯中「詞匯」(Vocabulary)(亦稱「特徵」Signature)的概念,一個「邏輯結構」(亦稱「模型」)的「詞匯」就是指描述該結構特性所要用到的各種特定常項、集合、函數或關係符號的集合。舉例說,在抽象代數學上,整數集與加法運算構成一個「群」(Group)。如果我們把這個群看成一個邏輯結構,那麼這個結構的「詞匯」便包括一個代表「加法單位元」的常項符號"0"以及一個代表「加法運算」的二元函數符號"+"。
現在設M和N為兩個具有相同詞匯的邏輯結構,為簡化討論,我們把這兩個結構的論域也分別記作M和N,另設r為正整數,以下讓我們定義一個以M和N為對象、長度為r的博奕,記作Gr(M, N)。這個博奕共有r個回合,在每個回合中,F先從論域M或N中選出一個元素,然後V從F沒選的那個論域中選出一個元素,這樣在第i個回合中兩名對奕者從兩個論域中各選出一個元素,記作mi和ni。
完成r個回合後,我們便得到M的子集M' = {m1 ... mr}、N的子集N' = {n1 ... nr}以及有序對集合:{(m1, n1) ... (mr, nr)} (任意兩個mi和mj以及任意兩個ni和nj可能指稱同一個元素),我們可以把上述有序對集合看成一個從M'到N'的「映射」f。如果我們把M和N原有的詞匯分別賦予上述子集M'和N',那麼便可得到M和N的「子結構」(仍記作M'和N')。現在如果上述映射f是一個「同構」,即f是一個「一一到上函數」,而且保留M'和N'的等同關係和結構,即任選M'和N'詞匯中的某成員P,以及M'的某個子集{mi ... mj},使得這個子集的基數等同於P的論元數目,有
則V勝F負,否則F勝V負。如果在Gr(M, N)中V有必勝策略,我們便記作M ≡r N。
以下用「圖論」(Graph Theory)上的一個例子以作說明。一個「圖」(Graph)由兩個集合VERTEX和EDGE組成,其中VERTEX是「點」的集合,EDGE則代表「邊」,可被處理成「點」之間的二元關係,表達為一個有序對集合,(v1, v2) ∈ EDGE代表v1和v2之間有一條邊連接。如果我們把圖看成某種邏輯結構,那麼這個邏輯結構的論域就是VERTEX,而這個結構的詞匯則是EDGE (註8)。現在我們進行Gr(A, B),其中A和B如下圖所示:

以下讓我們證明,對於G2(A, B),V有必勝策略;而對於G3(A, B),則F有必勝策略。首先考慮G2(A, B),設F兩次在同一論域中選擇不同的元素,設為b1、b3,那麼V只須在另一論域中選擇不同的元素,設為a2、a1,那麼{(a2, b1), (a1, b3)}是一個同構,這是因為上述映射(記作f)滿足:
如果F兩次均選擇同一論域中的同一個元素,設為a1,那麼V只須在另一論域中兩次選擇同一個元素,設為b2,容易看到{(a1, b2)}是一個同構。如果在F選了第一個元素,設為b2,並在V也選了第一個元素,設為a1後,F接著以V剛選的a1作為其第二個元素,那麼V只須以F選過的b2作為其第二個元素,容易看到{(a1, b2)}是一個同構。最後,如果在F選了第一個元素,設為b2,並在V也選了第一個元素,設為a1後,接著F以V沒選過的a2作為其第二個元素,那麼V只須以F沒選過的b3作為其第二個元素,容易看到{(a1, b2), (a2, b3)}是一個同構。從以上討論可見,無論F怎樣選,V都能勝出,即V有必勝策略。
其次考慮G3(A, B),如果F三次從B中選擇各不相同的點,即B' = {b1, b2, b3},則V必須三次從A中選擇點,其中必有重複,因而必有|A'| < |B'|。由於|A'| ≠ |B'|,這兩個子集不可能同構,所以F有必勝策略。
在本小節,筆者要介紹下文的定理要用到的兩個概念-「量詞深度」和「前束範式」。「量詞深度」(Quantifier Depth)量度一階語句所含量詞層次的數目。設p為一階語句,我們可以遞歸地定義p的量詞深度Depth(p)如下:
以下讓我們看一個例子,設p = ∀x (∃y (~R(x, y)) ∧ ∀z (P(x, z)))。憑觀察可以看出p含有兩層量詞,最外層是"∀x",第二層則是由"∃y"和"∀z"組成的合取式。我們也可以應用以上遞歸定義求Depth(p)如下:
| Depth(∀x (∃y (~R(x, y)) ∧ ∀z (P(x, z)))) | ||
| = | Depth(∃y (~R(x, y)) ∧ ∀z (P(x, z))) + 1 | 應用5 |
| = | max(Depth(∃y (~R(x, y))), Depth(∀z (P(x, z)))) + 1 | 應用3 |
| = | max(Depth(~R(x, y)) + 1, Depth(P(x, z)) + 1) + 1 | 應用6和5 |
| = | max(Depth(R(x, y)) + 1, Depth(P(x, z)) + 1) + 1 | 應用2 |
| = | max(0 + 1, 0 + 1) + 1 | 應用1 |
| = | max(1, 1) + 1 | |
| = | 1 + 1 | |
| = | 2 |
「前束範式」(Prenex Normal Form)則是一階語句的某種特定形式,我們說一階語句p表現為「前束範式」當且僅當p由前後兩部分組成,前一部分是一串量詞,稱為「前綴」(Prefix),後一部分則是不含任何量詞的公式,稱為「主體」(Matrix)。舉例說,
便表現為「前束範式」,其中"∀x∃y∃z"就是「前綴」,"q(y) ∨ (r(z) ⇒ p(x))"就是「主體」;而
卻不表現為「前束範式」,儘管以上兩式在邏輯上是等價的。
根據謂詞邏輯,任何一階語句都可應用以下等價關係轉換為等價的前束範式:
請注意在上述等價式1至4中,x不得在q中「自由出現」(即不受任何量詞約束),否則須先把q中自由出現的x轉換為另一個自由變項,然後才可應用這四條等價式。此外,在轉換過程中,常常還要運用現代數理邏輯中某些常用的定義或等價式,例如"⇒"的定義、交換律、結合律等。以下是把(40)轉換為(39)的步驟:
| ∀x (∃y(q(y)) ∨ (∀z(r(z)) ⇒ p(x))) | ||
| ≡ | ∀x (∃y(q(y)) ∨ (~∀z(r(z)) ∨ p(x))) | 應用"⇒"的定義 |
| ≡ | ∀x (∃y(q(y)) ∨ (∃z(~r(z)) ∨ p(x))) | 應用5 |
| ≡ | ∀x (∃y(q(y)) ∨ ∃z (~r(z) ∨ p(x))) | 應用4 |
| ≡ | ∀x (∃y (q(y) ∨ ∃z (~r(z) ∨ p(x)))) | 應用4 |
| ≡ | ∀x (∃y (∃z (~r(z) ∨ p(x)) ∨ q(y))) | 應用交換律 |
| ≡ | ∀x (∃y (∃z (~r(z) ∨ p(x) ∨ q(y)))) | 應用4和結合律 |
| ≡ | ∀x (∃y (∃z (q(y) ∨ ~r(z) ∨ p(x)))) | 應用交換律 |
| ≡ | ∀x∃y∃z (q(y) ∨ (r(z) ⇒ p(x))) | 應用結合律和"⇒"的定義,並略去不必要的括號 |
有了上述概念,我們便可以介紹本節的主要定理。為簡化以下定理的證明,在以下定理的表述中,我們規定p表現為前束範式(根據上一小節的討論,任何一階語句p等價於某前束範式)。
定理1:設M和N為具有相同詞匯的邏輯結構,p為任何包含上述詞匯且表現為前束範式的一階語句且Depth(p) = r,若M ≡r N,則p在M中真當且僅當p在中N真。
以下讓我們證明上述定理的逆否命題,即假設p在M中真,但在N中假,並由此推出M ~≡r N。由於p表現為前束範式且Depth(p) = r,我們有
其中Qi = ∀或∃ (1 ≤ i ≤ r),p'為不含任何量詞的一階語句。根據上一小節的5和6,我們亦知
其中Qi' = ∃ (若Qi = ∀)或∀ (若Qi = ∃) (1 ≤ i ≤ r)。請注意由於p在N中假,必有~p在N中真,即
為證明M ~≡r N,我們證明F有必勝策略。開始時,F先觀察Q1和Q1',其中必有一個為∃,另一個為∀。不失一般性,設Q1 = ∃,那麼他便在M中選擇個體m1使得
請注意由於(41)成立,F必能作出上述選擇。接著V要在N中選擇一個個體n1,由於Q1' = ∀,不論n1是哪個個體,都有
請注意經過第一回合,我們把(41)和(42)轉化為(43)和(44),而(43)和(44)中的一階語句較前減少了一個量詞。
一般地,在第i回合,F先觀察Qi和Qi',其中必有一個為∃,另一個為∀,他便在相應的論域中選出一個個體,而V則在另一論域中選出一個個體,而且在他們作出選擇後,必有
兩人繼續如上所述進行博奕,每經過一回合,有關的一階語句都較前減少一個量詞,並且保證(45)和(46)成立。如是者直至完成第r回合後,有關的一階語句變成原子公式,並且有
其中(48)等同於
由於p'是包含上述詞匯的一階語句,(47)和(49)告訴我們{(m1, n1) ... (mr, nr)}不是同構,因此F勝V負,定理得證。
以下用一個圖論上的例子來說明上述證明思路,設有以下的圖A及B:

根據上圖,我們有
請注意p是包含圖論詞匯的一階語句,其意思是每一點x都有至少兩個不同的點y和z與它相連。由於p在A中真但在B中假,根據「定理1」,在博奕G3(A, B)中,F有必勝策略。現在我們可以開始進行博奕,首先,由於(51)的第一個量詞是"∃",F在B中選出個體b1,V則在A中任選一個個體,設為a1,並且有
其次,由於(52)的第一個量詞是"∃",F在A中選出個體a2,V則在B中任選一個個體,設為b4,並且有
最後,由於(54)的第一個量詞是"∃",F在A中選出個體a4,V則在B中任選一個個體,設為b3,並且有
由於(56)和(57)同時成立,由此可知{(a1, b1), (a2, b4), (a4, b3)}不是同構,因此F勝。
「定理1」的價值在於提供了一種證明「一階不可定義性」的簡便方法。設有某性質P,若P可用一個一階語句p定義,而且Depth(p) = r,那麼根據「定理1」,對任何具有p所含詞匯的邏輯結構M和N而言,若M ≡r N,則p在M中真當且僅當p在N中真。由此可以得到「定理1」的一個推論:如要證明P不能由任何一階語句定義,我們只須證明,對任何自然數r,都可找到兩個結構M和N,使得M ≡r N,並且P在M中真,但在N中假,以下讓我們把上述證明方法應用於兩個範疇。
上述「定理1」的推論可用來證明某些量詞是一階不可定義的,首先考慮<1>型量詞。如果我們把<1>型量詞看成邏輯結構,那麼這類結構所用到的詞匯就只有一個集合A (即量詞的論元),這個集合把論域U劃分為兩個「部分」(Part):A和~A。由此我們有以下定理。
定理2:設有兩個論域U和U'以及集合A ⊆ U和A' ⊆ U',則U ≡n U'當且僅當以下條件成立:
以下讓我們證明上述定理。首先設(58)成立,那麼V有必勝策略:在每一回合,如果F在某一論域的某個部分選擇一個先前選過/沒有選過的個體,那麼V只需在另一論域的相應部分選擇一個先前選過/沒有選過的個體。請注意由於U和U'兩個相應部分的基數要麼相等,要麼同時大於n,V必能作出上述選擇。由此可見,在每個回合中,F和V所選的個體必然同時屬於A和A',或者同時屬於~A和~A'。因此,經過n個回合後,從U和U'取得的兩個子集必然同構,即V勝。
其次設(58)不成立,這有幾種可能情況。為簡化討論,這裡只考慮一種情況,即|A| < n並且|A'| ≥ n。在此情況下,F有必勝策略:在首|A|個回合,F選擇A中不同的個體,V為了保持不敗,必須選擇A'中不同的個體。從第|A| + 1個回合起,F選擇A'中先前沒有被選過的個體,這時A中所有個體都已被選過,V只有兩種選擇,要麼選擇A中先前已選過的個體,要麼選擇~A中的個體,但無論是何種選擇,都勢必令所得U和U'的兩個子集不同構,即F勝。定理至此乃得證。
綜合「定理1」的推論和「定理2」,我們便得到證明<1>型量詞Q為一階不可定義的方法:找出兩個論域U和U'以及集合A ⊆ U、A' ⊆ U'使得(58)成立並且QU(A) ~⇔ QU'(A'),這個證明方法其實就是筆者在《廣義量詞系列:量詞的邏輯性質》中介紹過的「定理12」,當時沒有提供證明,現在我們看到該定理可從博奕論推導出來。
我們還可以把上述內容推廣至其他單式量詞,這些邏輯結構的詞匯包含k個集合(k ≥ 2),把論域劃分為2k個部分。由此可以把「定理2」推廣為
定理3:設有兩個論域U和U',各自含有k個集合A1...Ak以及A'1...A'k,把所屬論域劃分為2k個部分,則U ≡n U'當且僅當以下條件成立:
由此可以把前述<1>型量詞一階不可定義性的證明方法推廣至其他單式量詞。設Q為含有k個論元的單式量詞,如要證明Q為一階不可定義,我們可以對任何自然數n,找出兩個論域U和U'以及集合U中k個集合A1...Ak以及U'中k個集合A'1...A'k,使得(59)成立並且QU(A1, ... Ak) ~⇔ QU'(A'1, ... A'k)。
現在讓我們證明<12,1>型量詞"(more ... than ...)"是一階不可定義的,這個量詞含有3個論元,所以我們要考慮23 = 8個部分。但這並不構成很大困難,因為根據這個量詞的真值條件,我們只需集中考慮U中的A ∩ B ∩ C、A ∩ C − B和B ∩ C − A這三個部分以及U'中的相應部分,例如我們可以構造以下模型:
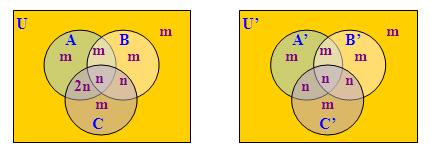
在上述模型中,各個相應部分的基數要麼相等,要麼都不小於n,而且由於|A ∩ C| = 3n、|B ∩ C| = 2n、|A' ∩ C'| = 2n、|B' ∩ C'| = 2n,我們有(more ... than ...)(A, B)(C)並且~(more ... than ...)(A', B')(C'),由此證得"(more ... than ...)"是一階不可定義的。
上述「定理1」的推論還可用來證明圖論上的某些性質是一階不可定義的,「連通性」(Connectivity)就是其中之一,我們說一個圖是「連通」的當且僅當其上任何兩點之間都有一條「路徑」把它們連接起來。我們可以這樣來證明「連通性」是一階不可定義的,對任何自然數r,構造兩個圖A和B,使得A是連通的,B是不連通的,並且A ≡r B。事實上,給定r,只要A和B各有至少2r + 2個點,我們總能構造所需的圖(證明從略)。以下讓我們驗證r = 3的情況,在此一情況下,A和B須各有至少23 + 2 = 10個點,我們可以構造以下兩個圖:

為證明A ≡3 B,我們須提供V的必勝策略,但這裡須先提供圖論中「距離」(Distance)的定義。在一個圖上,兩點之間的距離是指從其中一點走至另一點所須通過的邊的最小數目。如果兩點之間不連通,我們便規定這兩點之間的距離為∞。以上圖為例,a1和a9的距離是2 (而非8),b3和b6的距離則是∞。
至此我們可以給出V的必勝策略如下:在第一回合,在F作出選擇後,V可隨意選擇。在第二回合,如果F所選的點與第一回合中所選的某一點相距n (其中n為0、1或2),則V所選的點也須與第一回合中所選的另一點相距n;如果F所選的點與第一回合中所選某一點的距離大於2,則V所選的點與第一回合中所選另一點的距離也須大於2。在第三回合,V只要因應F作出適當的選擇便可獲勝。
以下用兩個博奕實例來說明上述策略。在第一個例子中,設F和V在第一回合分別選擇a1和b1。在第二回合,設F選擇b4,由於b4與b1的距離為2,V必須選擇a3或a9 (請讀者想想如果V不這樣選,F將可在第三回合如何令V落敗),設V選了a3。在第三回合,設F選擇a4,這時V須選擇b3。容易驗證{(a1, b1), (a3, b4), (a4, b3)}是一個同構。
在第二個例子中,設F和V在第一回合分別選擇a4和b4。在第二回合,設F選擇b6,由於b4與b6的距離為∞,V必須在A中選擇一個與a4相距大於2的點 (請讀者想想如果不這樣選,F將可在第三回合如何令V落敗),設V選了a7。在第三回合,設F選擇a10,這時V只須選擇不與b4和b6相鄰的點,例如b1。容易驗證{(a4, b4), (a7, b6), (a10, b1)}是一個同構。
至此筆者介紹了結構博奕的應用,請注意以上所述的證明方法只能用來證明一階邏輯系統下的不可定義性,對於「一階(量詞)邏輯」系統或者其他更複雜的邏輯系統,需要定義更複雜的博奕規則。此外,博奕論在語言學上還有其他應用,本文無法一一介紹。


